February 4, 2026
Tutorial
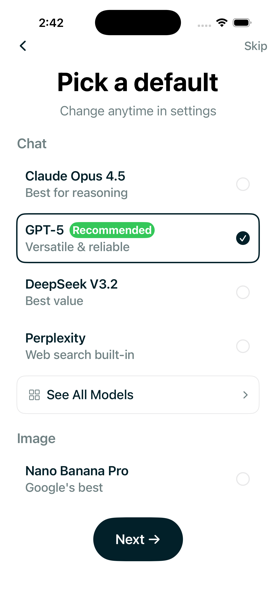
How to Set Your Default AI Model
Tired of model roulette? Pick your default model and keep it. GPT-4o, Claude, or any of 300+ models.
Read moreNotes on building Chat Labs 1AI. Getting 300+ AI models to work together. What breaks, what works, what I learned.
Tired of model roulette? Pick your default model and keep it. GPT-4o, Claude, or any of 300+ models.
Read more
Language models struggle with information in the middle of long contexts. The U-shaped attention pattern. Paper #30.
Read more
Combining retrieval with generation. External knowledge grounds language models in facts. Paper #29.
Read more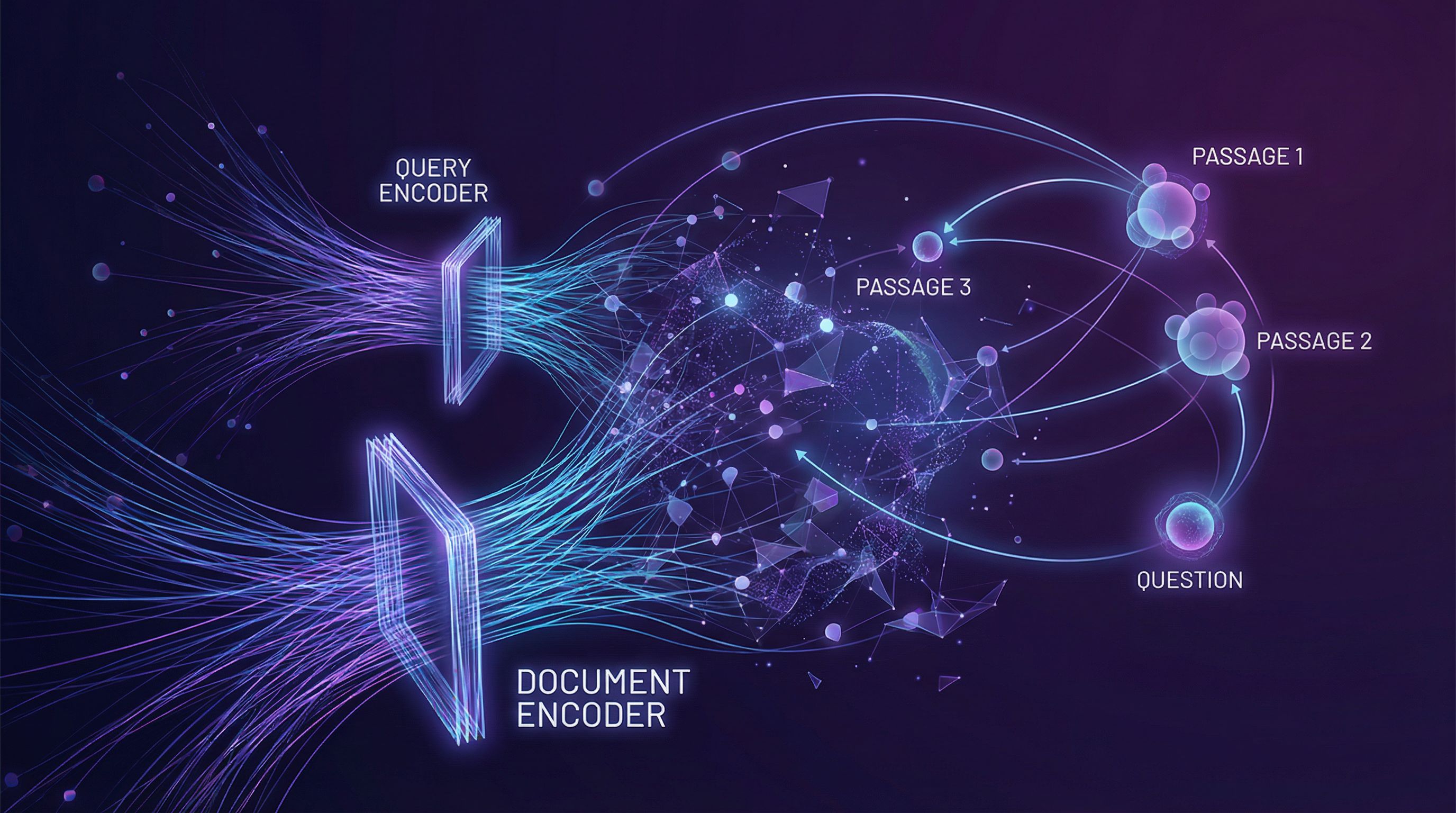
Learning embeddings for questions and passages. Dual encoders and contrastive learning beat BM25. Paper #28.
Read more
Predicting multiple tokens at once improves sample efficiency and enables speculative decoding. Paper #27.
Read more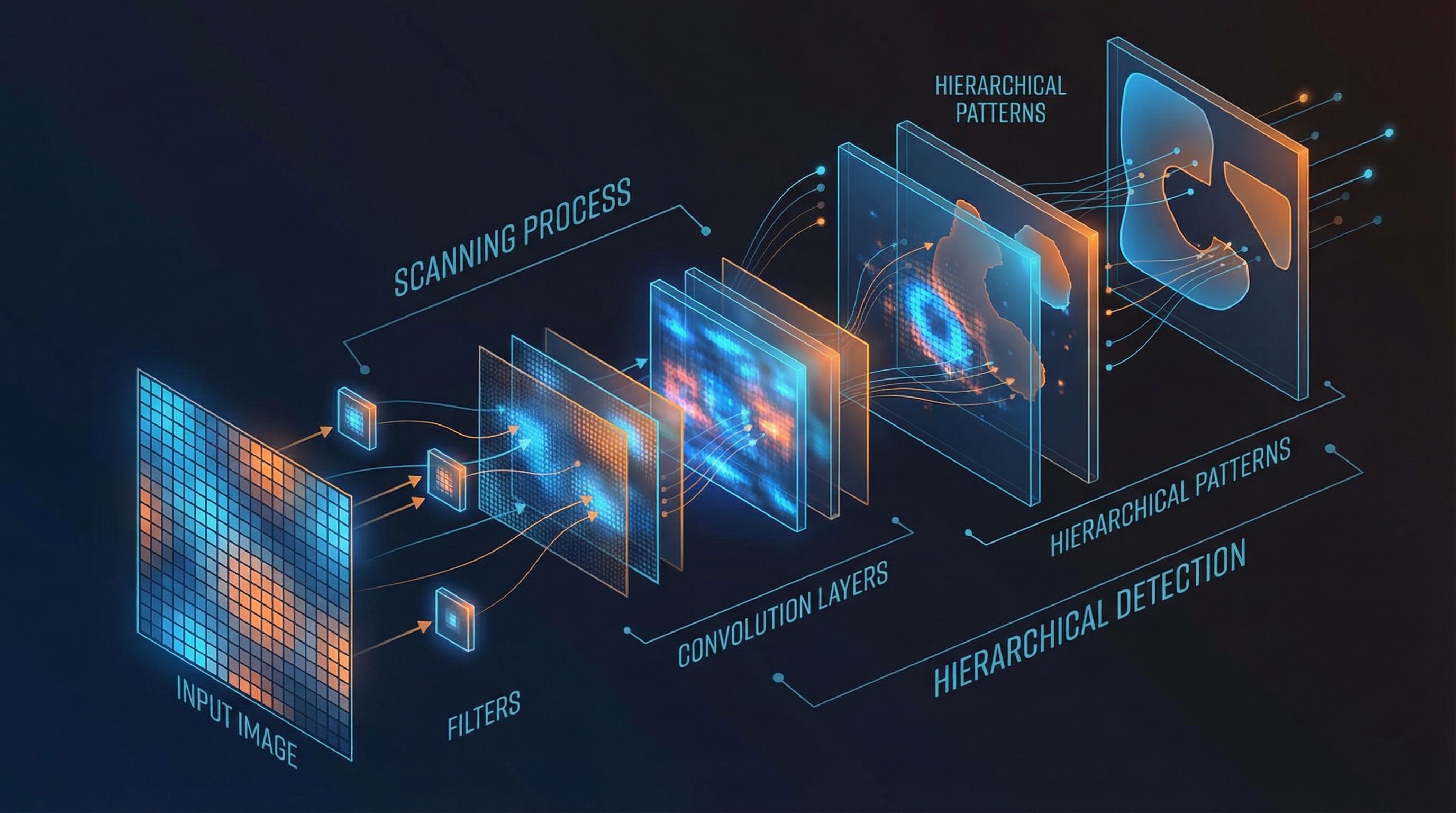
Convolutional layers, pooling, ReLU, and backpropagation. Stanford's CS231n course distilled. Paper #26.
Read more
The shortest program that outputs a string. Incompressibility equals randomness. Paper #25.
Read more
Formal definitions of machine intelligence. Recursive self-improvement and the path to superintelligence. Paper #24.
Read more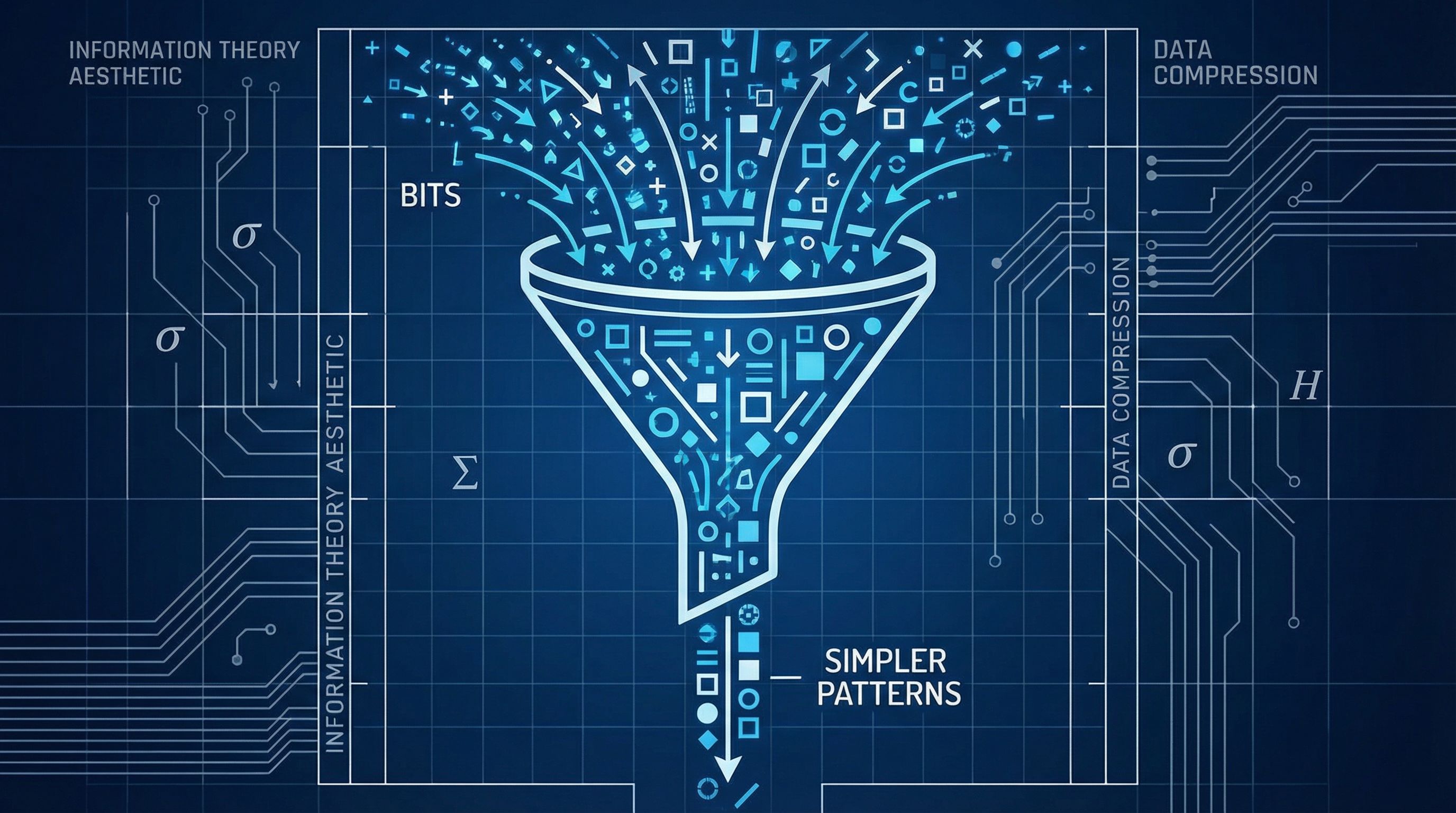
Minimum Description Length balances model complexity against fit. Occam's razor made mathematical. Paper #23.
Read more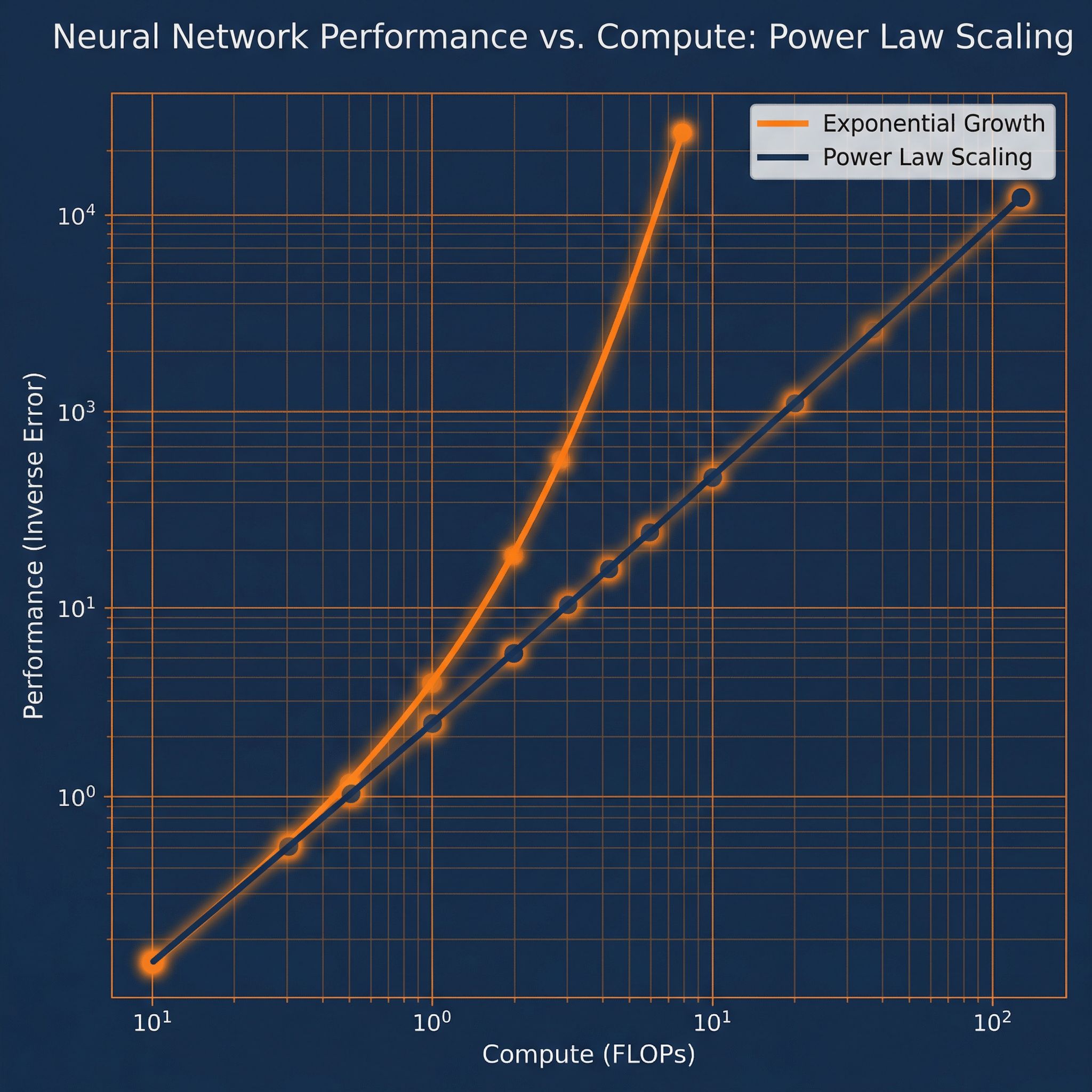
Power laws for neural language models. How performance scales with compute, data, and parameters. Paper #22.
Read more
Training speech models without frame-level alignment. The blank token and alignment-free learning. Paper #21.
Read more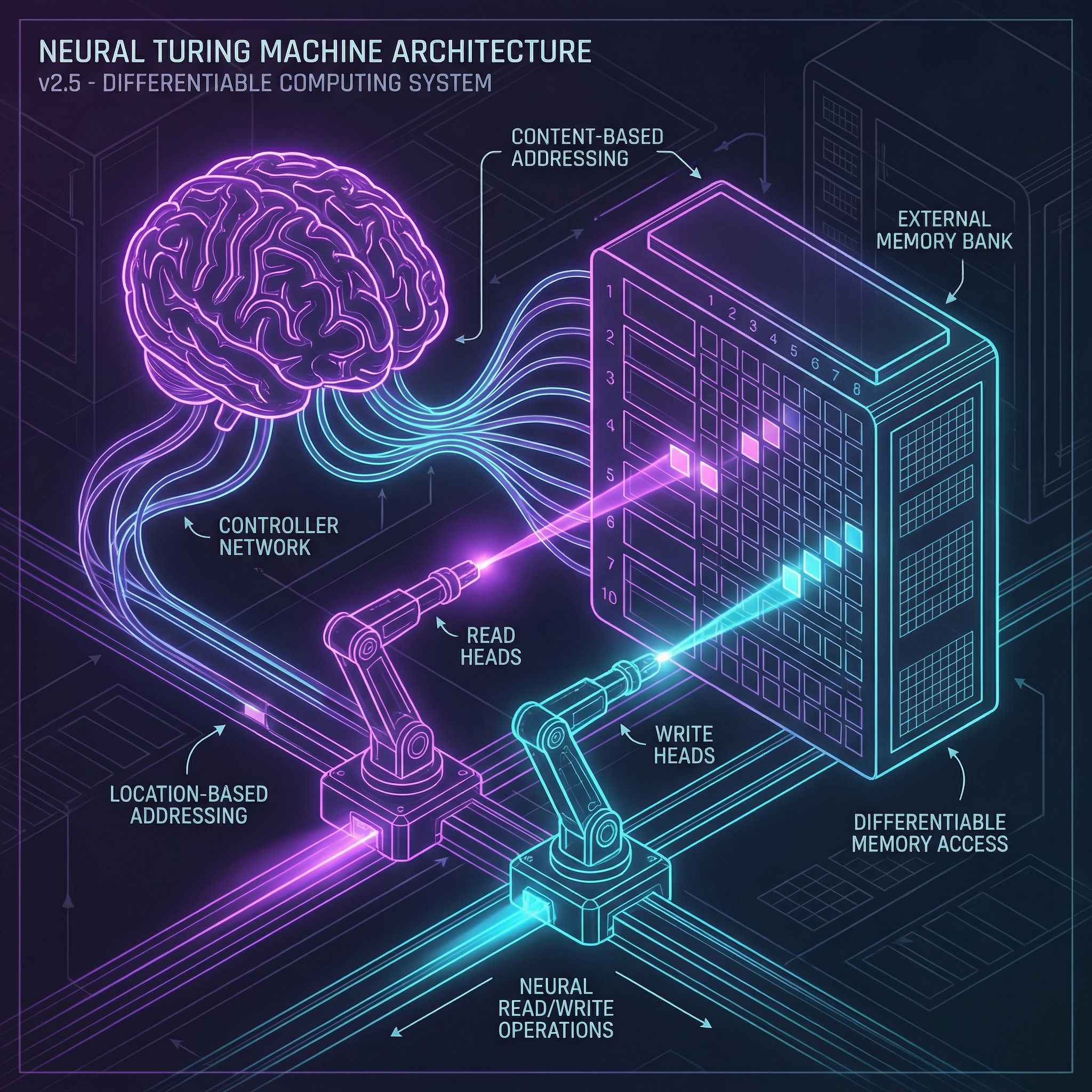
Differentiable computers with external memory banks. Content and location-based addressing. Paper #20.
Read more
Why does coffee mix but never unmix? Entropy, coarse-graining, and the arrow of time. Paper #19.
Read more
Memory slots that attend to each other enable multi-step reasoning. Paper #18.
Read more
Learning to generate data by encoding it into structured latent spaces. ELBO and the reparameterization trick. Paper #17.
Read more
Relation Networks compare all object pairs to answer questions about relationships. Paper #16.
Read more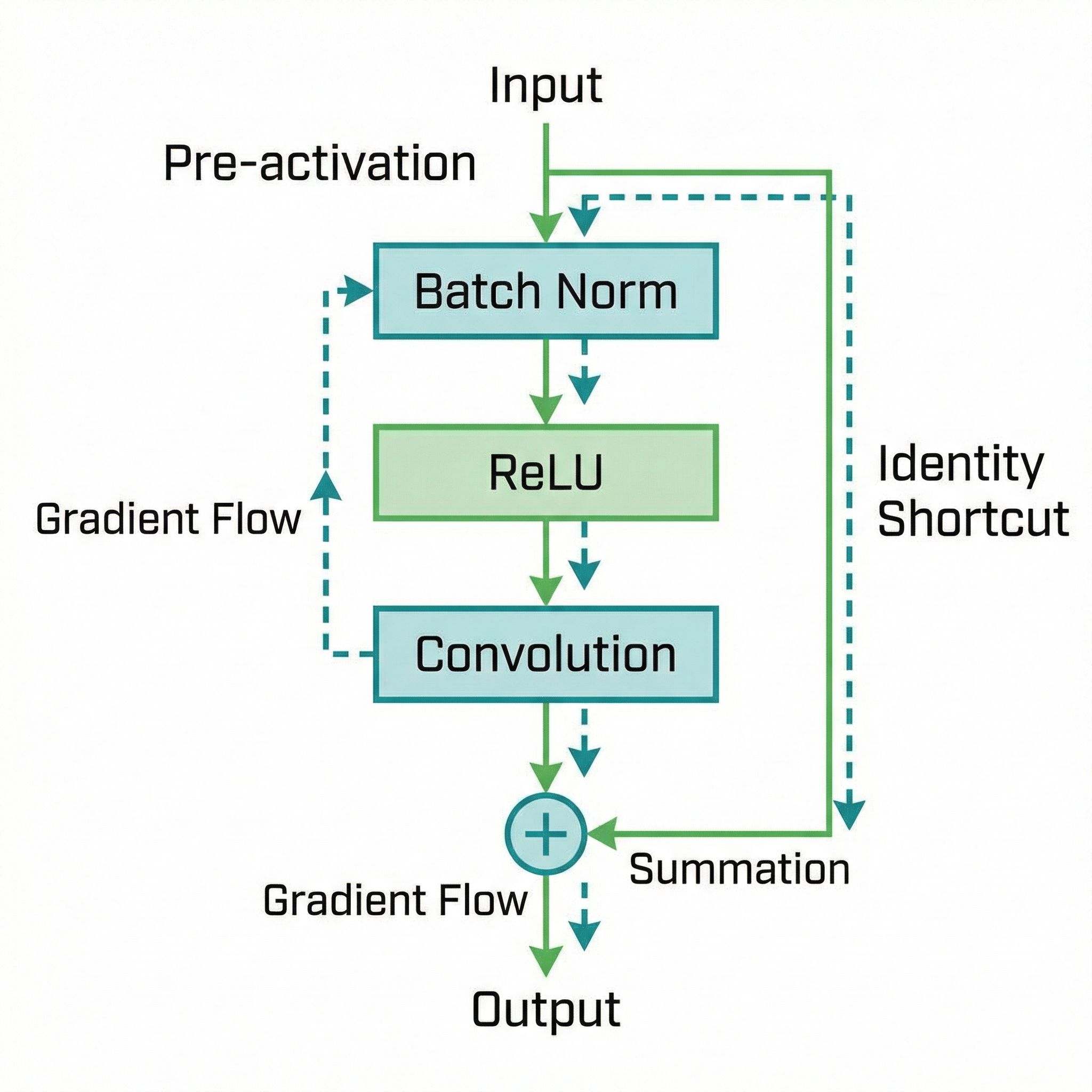
Moving activation before convolution enables training 1000-layer networks. Paper #15.
Read more
Neural machine translation by jointly learning to align and translate. The original attention mechanism. Paper #14.
Read more
The Transformer architecture replaced recurrence with self-attention. Foundation of GPT, BERT, and modern AI. Paper #13.
Read more
Message passing on graphs. Nodes aggregate information from neighbors to learn representations. Paper #12.
Read more
Exponentially expanding receptive fields without losing resolution. WaveNet's secret for audio generation. Paper #11.
Read more
Skip connections let gradients flow through 152 layers. Learning residuals instead of direct mappings. Paper #10.
Read more
Pipeline parallelism for training giant neural networks. Micro-batches keep accelerators busy. Paper #9.
Read more
Sets have no order, but neural networks need sequences. How to handle permutation invariance. Paper #8.
Read moreGPT-5.2 feels less like a tool and more like a patronizing hall monitor. When "just do the task" becomes a premium feature.
Read more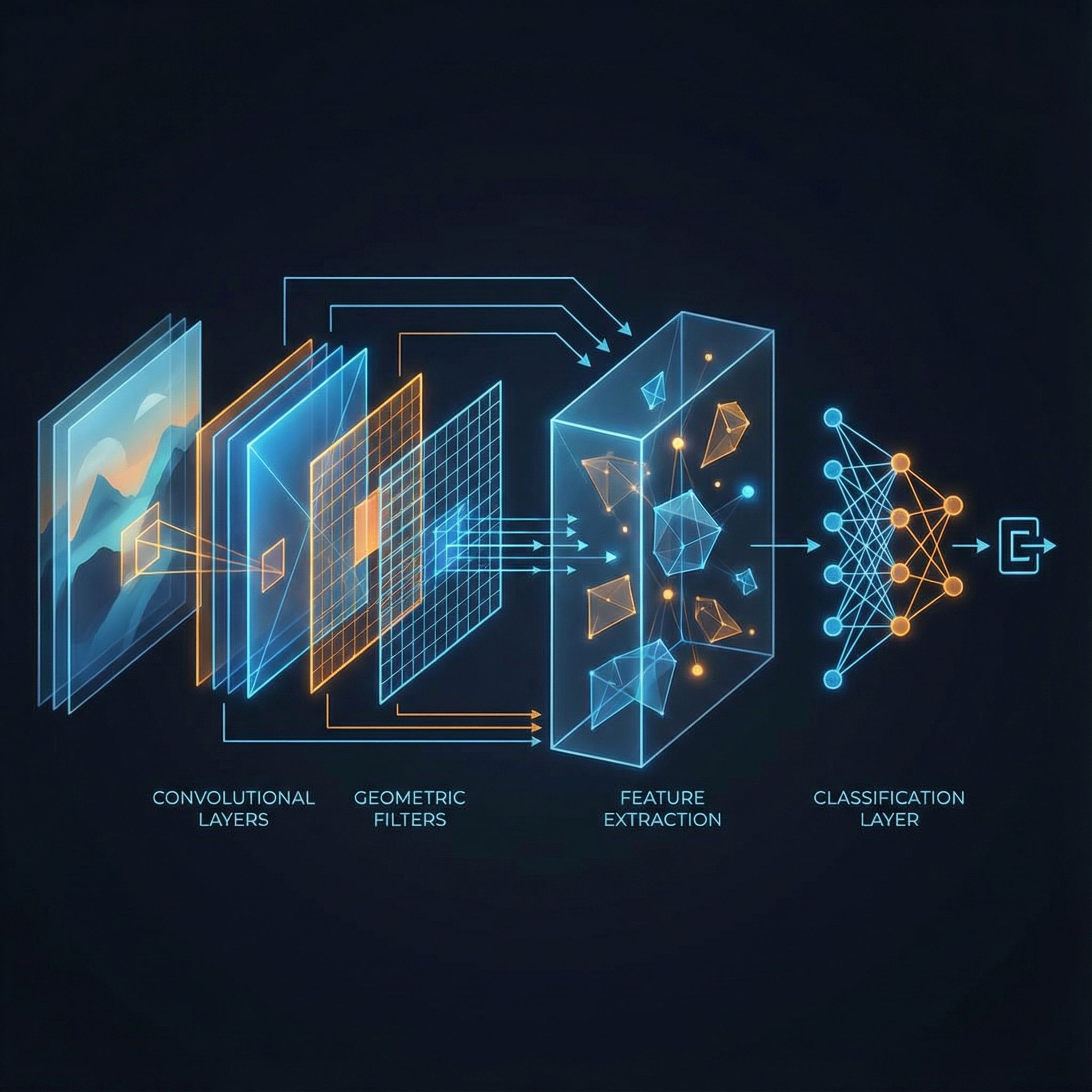
Krizhevsky, Sutskever, and Hinton's 2012 ImageNet victory proved deep learning could outperform hand-engineered computer vision. Paper #7.
Read more
Vinyals, Fortunato, and Jaitly repurposed attention to point at input positions instead of blending hidden states. Paper #6.
Read more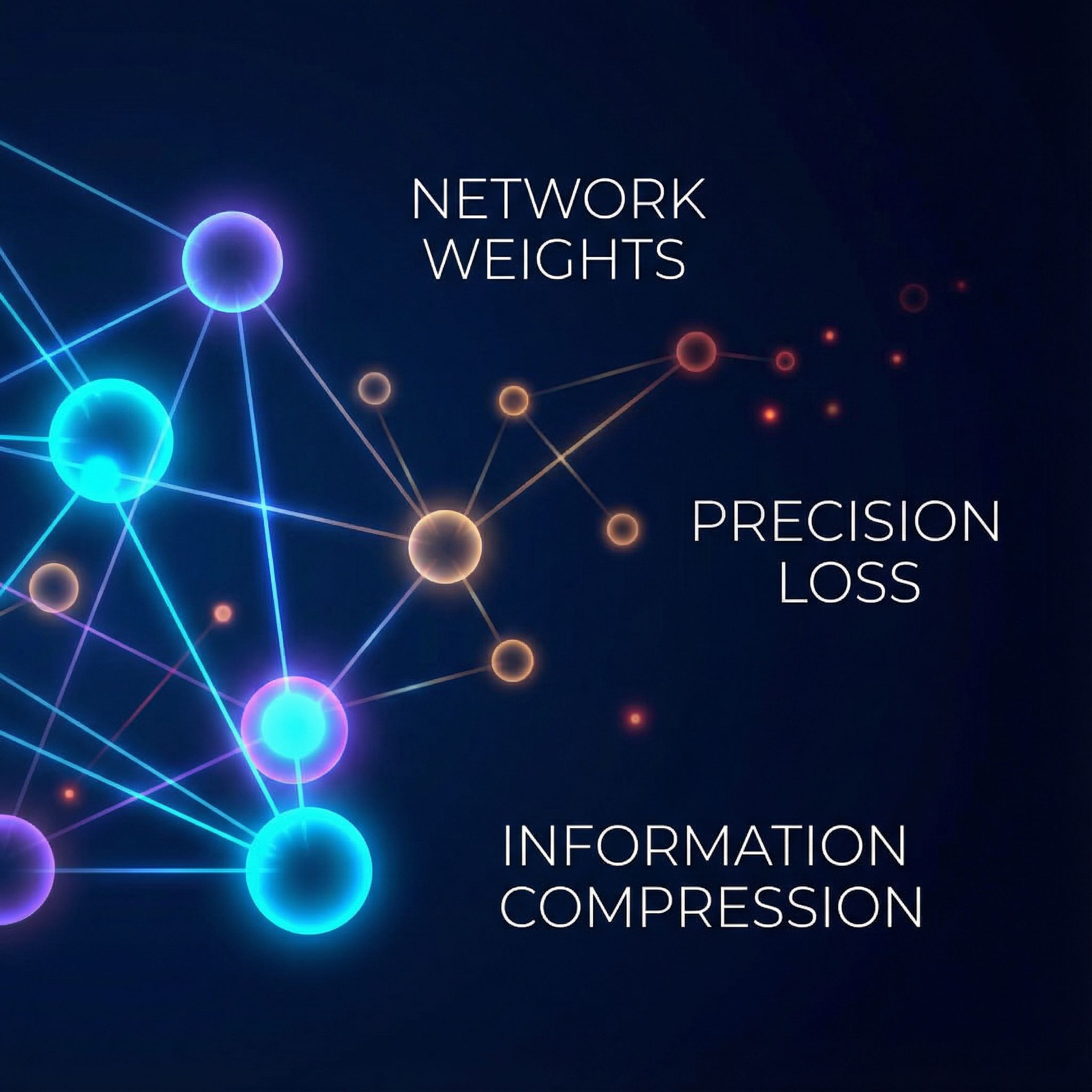
Hinton and van Camp showed that penalizing weight complexity leads to better generalization. Paper #5.
Read more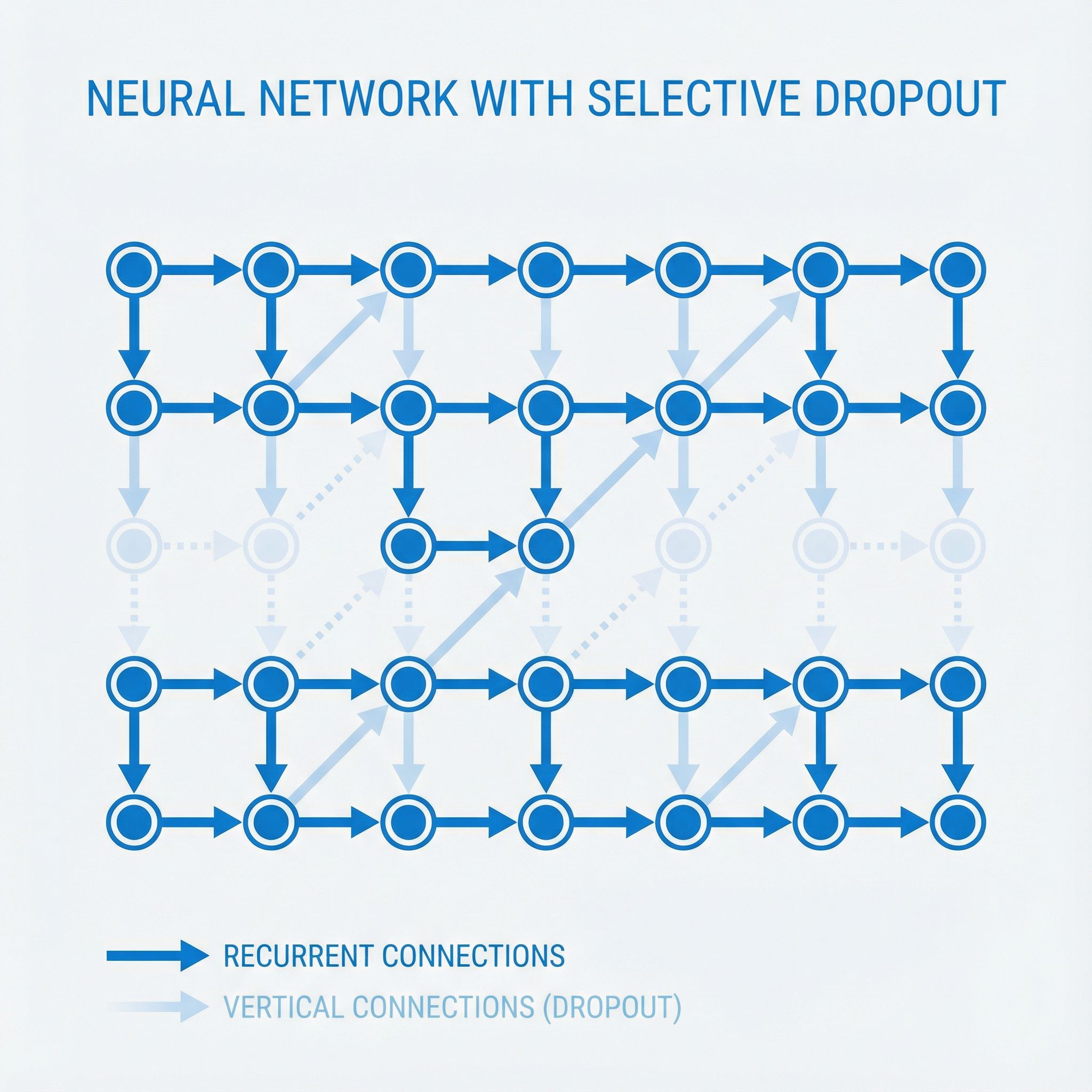
Zaremba, Sutskever, and Vinyals figured out how to apply dropout to LSTMs without breaking them. Paper #4.
Read more
Christopher Olah's 2015 post explained LSTM gates with clarity that textbooks lacked. Paper #3.
Read more
Karpathy's famous 2015 post showed RNNs could generate Shakespeare and Linux code by predicting one character at a time. Paper #2.
Read more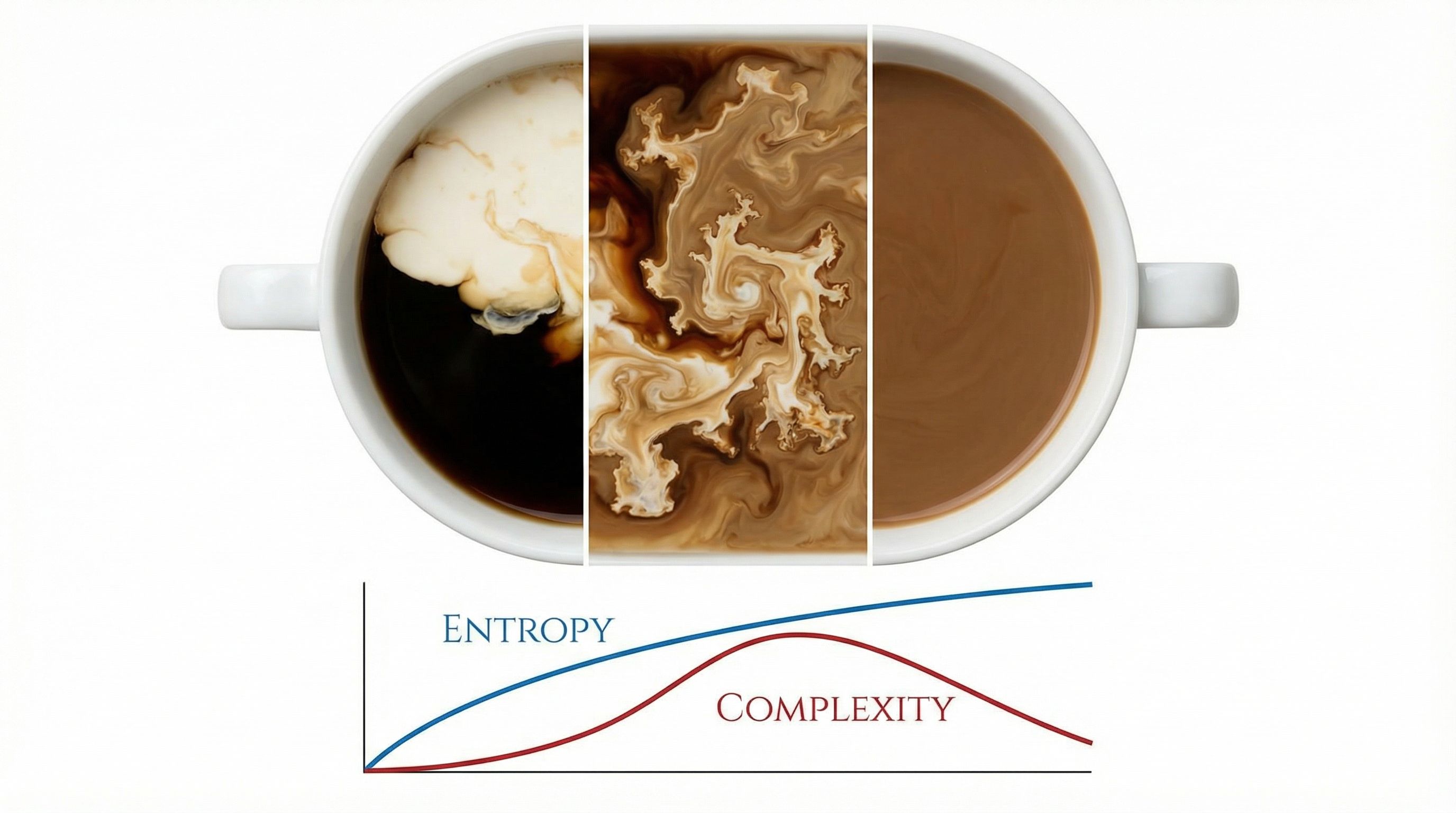
Scott Aaronson's First Law of Complexodynamics explains why complexity rises, peaks, then falls. Paper #1 from Sutskever's 30.
Read more
Got tired of copy-pasting AI responses into Slack. Built shareable links instead. One good prompt becomes team knowledge.
Read more
Scraped 10,000 custom instructions to see patterns. Set your style once -every model remembers.
Read moreI write when I ship something or figure something out. Maybe twice a month. No tracking, no growth hacks.
One-click unsubscribe.