Traditional search relies on keyword matching, where BM25 finds documents containing query terms. Dense Passage Retrieval learns semantic embeddings instead. Questions and passages live in the same vector space; retrieval becomes nearest-neighbor search.
Why Sutskever Included This
DPR enables semantic search, finding relevant documents by meaning, not just keywords. This powers question answering, knowledge-intensive NLP, and the retrieval component of RAG systems. Understanding DPR is prerequisite for modern retrieval-augmented generation.
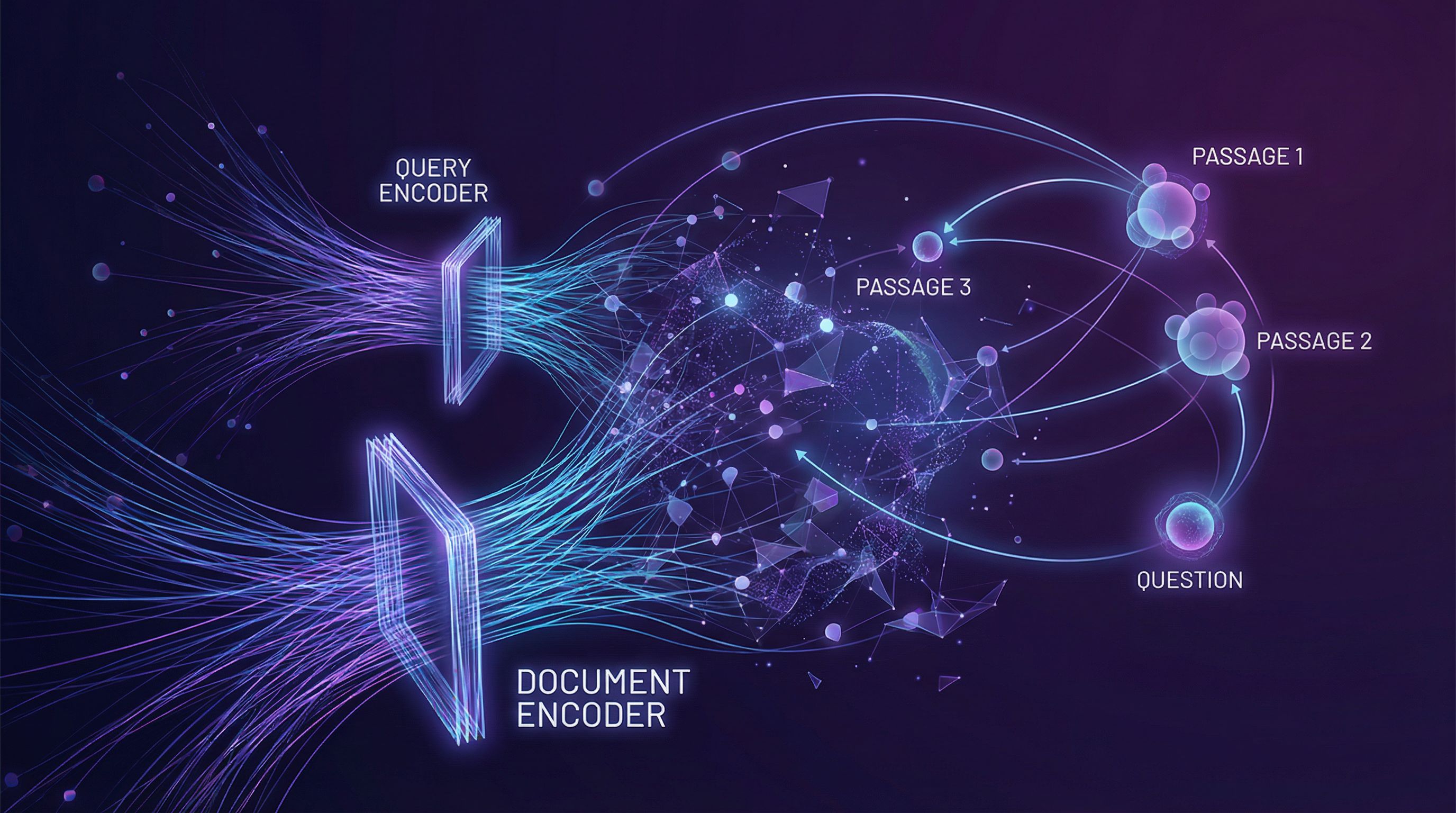
Dual Encoder Architecture
Two separate neural networks encode questions and passages into dense vectors. At retrieval time, find passages whose embeddings are closest to the question embedding:
sim(q, p) = E_Q(q) · E_P(p)
E_Q is the question encoder, E_P is the passage encoder. Similarity is the dot product of their outputs.
Separate encoders allow precomputing passage embeddings. At query time, only the question needs encoding; retrieval is fast approximate nearest neighbor search.
Contrastive Learning
Training maximizes similarity between questions and relevant passages while minimizing similarity to irrelevant ones. The loss function:
L = -log [exp(sim(q, p+)) / Σ exp(sim(q, p_i))]
where p+ is the positive passage and the sum includes negatives.
In-Batch Negatives
Clever efficiency trick: use other passages in the same training batch as negative examples. A batch of N (question, passage) pairs provides N-1 negatives for each question at no additional cost.
This eliminates the need for explicit negative sampling while providing hard negatives from related topics.
DPR vs BM25
BM25 matches keywords. It fails when questions and answers use different vocabulary. "What causes a cold?" won't match "Rhinoviruses spread through..."
DPR understands semantic similarity. Paraphrases, synonyms, and related concepts cluster together. On standard benchmarks, DPR achieves ~78% accuracy versus BM25's ~59%.
Scaling Retrieval
With millions of passages, exact nearest-neighbor search is slow. Approximate methods (FAISS, ScaNN) enable sub-linear retrieval through techniques like product quantization and hierarchical navigation.
Further Reading
More in This Series
Part of a series on Ilya Sutskever's recommended 30 papers.