Dropout works by randomly zeroing out neurons during training, preventing overfitting. When researchers tried applying it to RNNs, the networks stopped learning. This 2014 paper by Zaremba, Sutskever, and Vinyals found the problem and a fix.
Why Sutskever Included This
Sutskever is a co-author. LSTMs were powerful but overfit badly on small datasets, and standard dropout made things worse. This paper enabled the large-scale LSTM training that powered early neural machine translation and speech recognition.
The Problem with Naive Dropout
In feedforward networks, dropout works by randomly setting neurons to zero during training. At test time, you scale the weights to compensate. The network learns redundant representations and doesn't rely too heavily on any single neuron.
RNNs have recurrent connections: the hidden state at time t feeds into time t+1. If you apply dropout to these connections, you're randomly corrupting the memory that flows through time. Each step loses different information. After a few steps, the signal degrades into noise.
Early attempts at RNN dropout applied it uniformly to all connections. The networks trained poorly and the regularization benefit disappeared. Many researchers concluded dropout wasn't compatible with RNNs.
The Solution: Selective Dropout
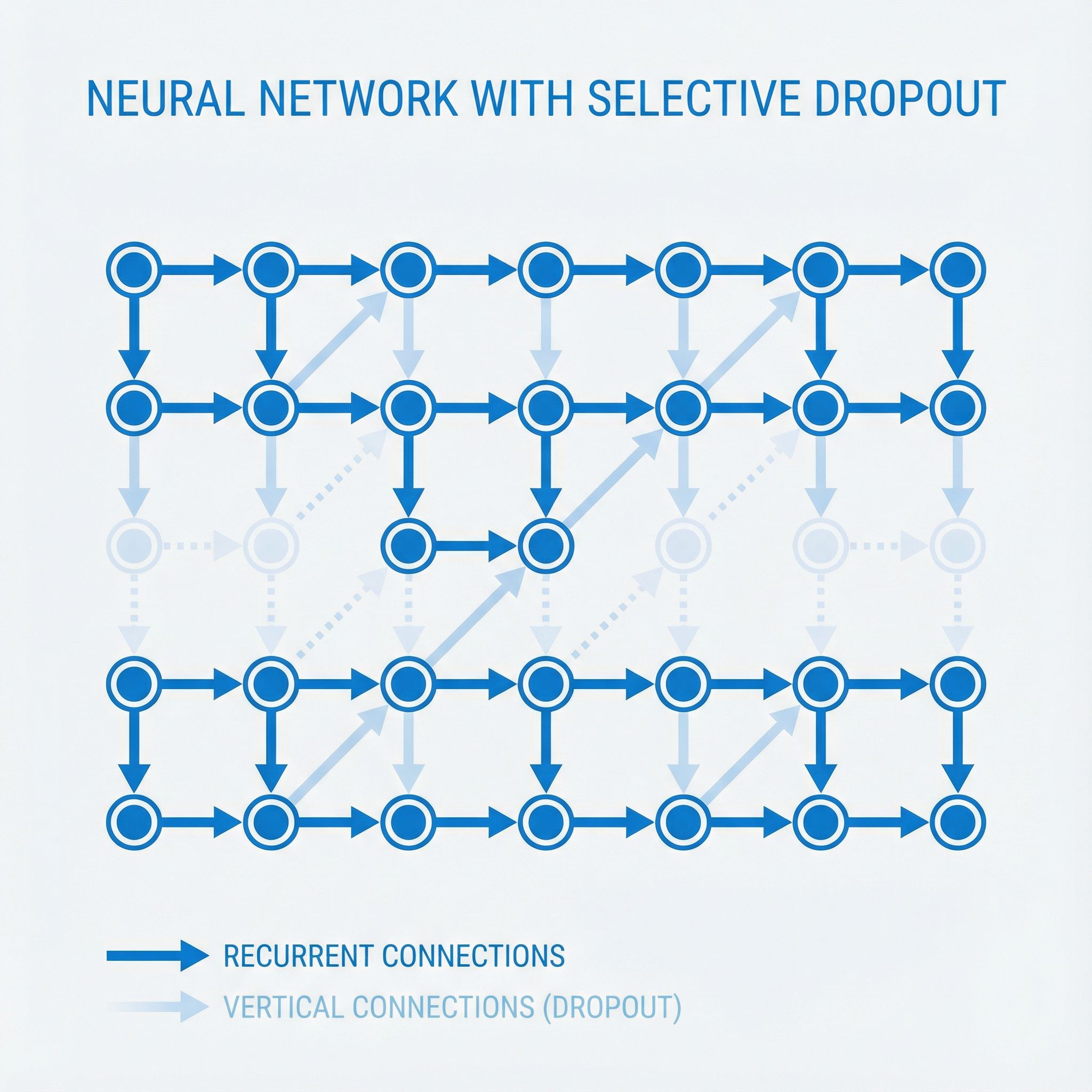
Apply dropout only to non-recurrent connections. The recurrent connections (hidden state to hidden state) stay intact. The input-to-hidden and hidden-to-output connections get dropout.
Visually, think of an RNN unrolled through time. The horizontal arrows (connecting timesteps) never get dropout. The vertical arrows (inputs coming in, outputs going out) do. This preserves the memory flow while still regularizing the input/output mappings.
# Naive dropout (breaks RNNs)
h_t = dropout(tanh(W_h · h_{t-1} + W_x · x_t))
# Correct dropout (works)
h_t = tanh(W_h · h_{t-1} + W_x · dropout(x_t))
y_t = W_y · dropout(h_t)
The dropout mask can change at each timestep (standard dropout) or stay fixed across the sequence (variational dropout, introduced in later work). Both approaches work better than naive dropout.
Results
The paper demonstrated gains on Penn Treebank language modeling, the standard benchmark of the era. Without dropout, LSTMs overfit quickly. Training perplexity kept dropping while validation perplexity increased. With proper dropout, both curves tracked together and final perplexity improved substantially.
The technique transferred to speech recognition and machine translation. Any task using LSTMs benefited.
Why This Mattered
Before this paper, training large LSTMs required massive datasets. Smaller datasets led to severe overfitting. This limited where LSTMs could be applied.
After this paper, researchers could train deeper, wider LSTMs on moderate-sized datasets without overfitting. This expanded the range of problems tractable with sequence models. The paper enabled the LSTM boom of 2014-2017, before transformers took over.
Connection to Modern Practice
Transformers use different regularization strategies like attention dropout and stochastic depth. But regularization must respect the architecture's structure. Techniques from feedforward networks don't transfer blindly to sequential or attention-based models.
A technique that "doesn't work" often just needs careful adaptation. Dropout wasn't incompatible with RNNs, just applied wrong.
The Author Connection
This is the first paper in Sutskever's list where he's an author (the previous three were blog posts by Aaronson, Karpathy, and Olah). Wojciech Zaremba, the first author, later co-founded OpenAI's robotics team. Oriol Vinyals went on to lead sequence-to-sequence research at Google Brain and later at DeepMind.
The paper shows Sutskever's preference for practical results. The insight seems obvious in retrospect, but it unblocked an entire line of research and enabled thousands of follow-on applications.
Further Reading
More in This Series
Part of a series on Ilya Sutskever's recommended 30 papers, connecting each to practical AI development.