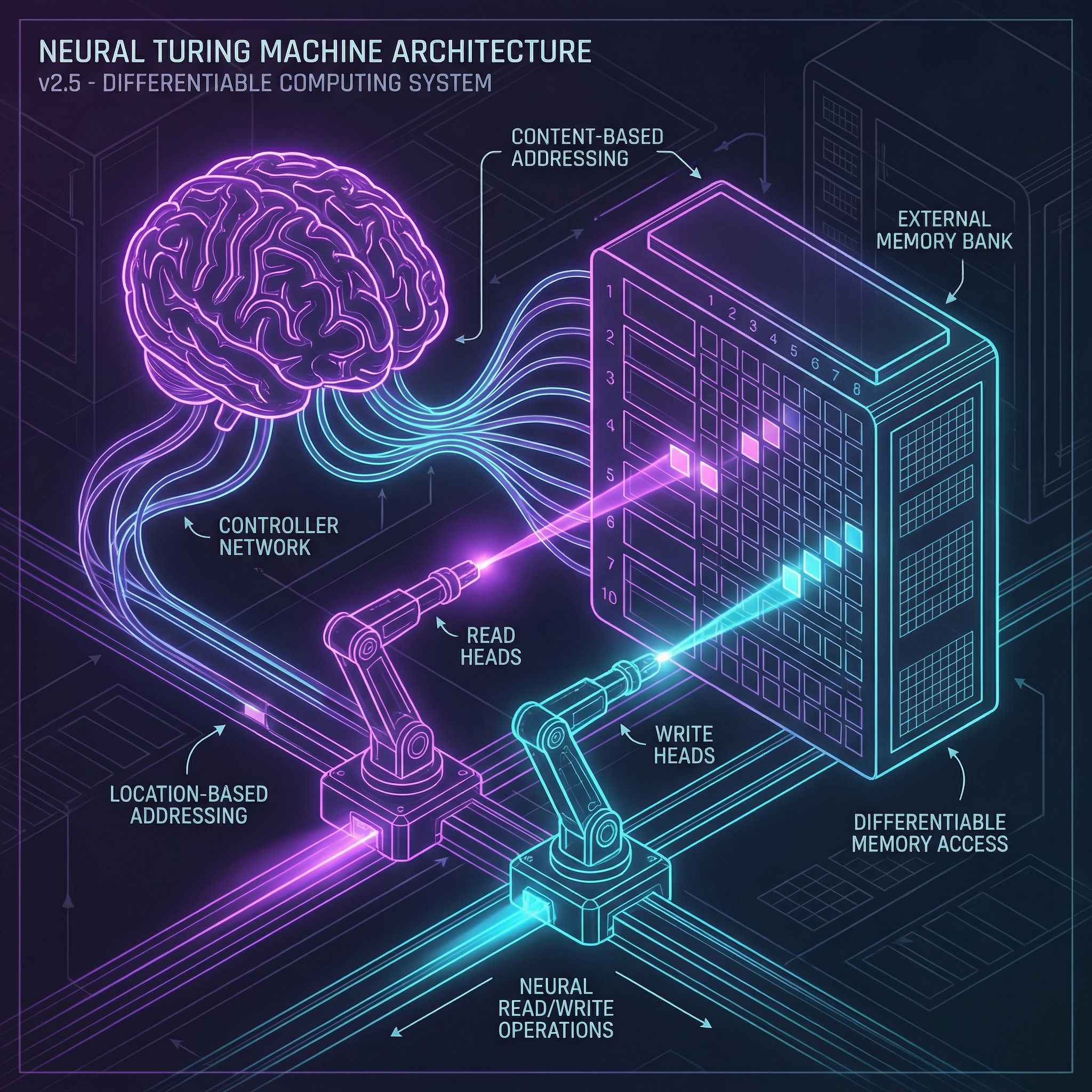
A Turing machine has a tape it can read and write. Neural networks have weights and activations. Neural Turing Machines add an external memory matrix that a neural controller can address, read, and write, all differentiable, all trainable with gradient descent.
Why Sutskever Included This
This paper from DeepMind asked: can neural networks learn algorithms? By adding addressable memory, NTMs can learn to copy sequences, sort lists, and perform simple computation. The architecture separates memory from computation, a design principle that influenced later work.
External Memory
The memory is an N × M matrix: N locations, each storing an M-dimensional vector. Unlike LSTM hidden states, this memory is large and explicitly addressable. The network can store data at location 17 and retrieve it later by addressing location 17.
All operations must be differentiable for backpropagation. Soft attention solves this: instead of addressing one location, produce a probability distribution over all locations. Read a weighted average; write proportionally to all locations.
Read and Write Heads
Read heads produce attention weights over memory locations, then output the weighted sum of memory contents. Multiple read heads allow parallel access to different information.
Write heads modify memory through erase and add operations:
Erase: M_t ← M_{t-1} ⊙ (1 - w ⊗ e)
Add: M_t ← M_t + (w ⊗ a)
w is the attention distribution, e is the erase vector, a is the add vector. Memory locations with high attention weight change more.
Content-Based Addressing
Find memory locations by what they contain. The controller produces a query vector. Compute cosine similarity between the query and each memory row. Apply softmax with a sharpness parameter to get attention weights.
Content addressing finds relevant data regardless of where it's stored. Useful when you need to retrieve by association rather than position.
Location-Based Addressing
Sometimes you need sequential access: read location 5, then 6, then 7. Location-based mechanisms enable this:
Interpolation: Blend content-based weights with the previous timestep's weights. Controls whether to search or continue from where you were.
Shift: Rotate the attention distribution by small amounts. Move attention forward or backward by one position.
Sharpening: Concentrate attention on fewer locations. Prevents weights from spreading too diffusely.
Learned Algorithms
The paper demonstrates NTMs learning to copy sequences, sort, and perform associative recall. The network isn't programmed with these algorithms; it discovers them through training.
Watching attention patterns reveals the learned algorithm: for copying, the read head scans through memory sequentially. For sorting, it jumps between locations based on content.
Limitations and Legacy
NTMs are hard to train. Gradients through soft attention can be noisy. Differentiable Neural Computers (DNCs) improved on NTMs with more stable memory allocation. Transformers achieved similar capabilities through self-attention without explicit memory structures.
The core insight persists: separating memory from computation expands what neural networks can learn.
More in This Series
Part of a series on Ilya Sutskever's recommended 30 papers.