ResNet's skip connections should let signals flow unimpeded. But the original design placed ReLU after the addition, blocking the identity path. Moving activation before convolution cleared the highway. The result: trainable 1000-layer networks.
Why Sutskever Included This
Paper #10 introduced ResNet. This follow-up paper refines the architecture with a subtle but significant change. The pre-activation design became standard for very deep networks and influenced transformer architectures (which place layer norm before attention).
The Original Design
In the first ResNet paper, each block looked like:
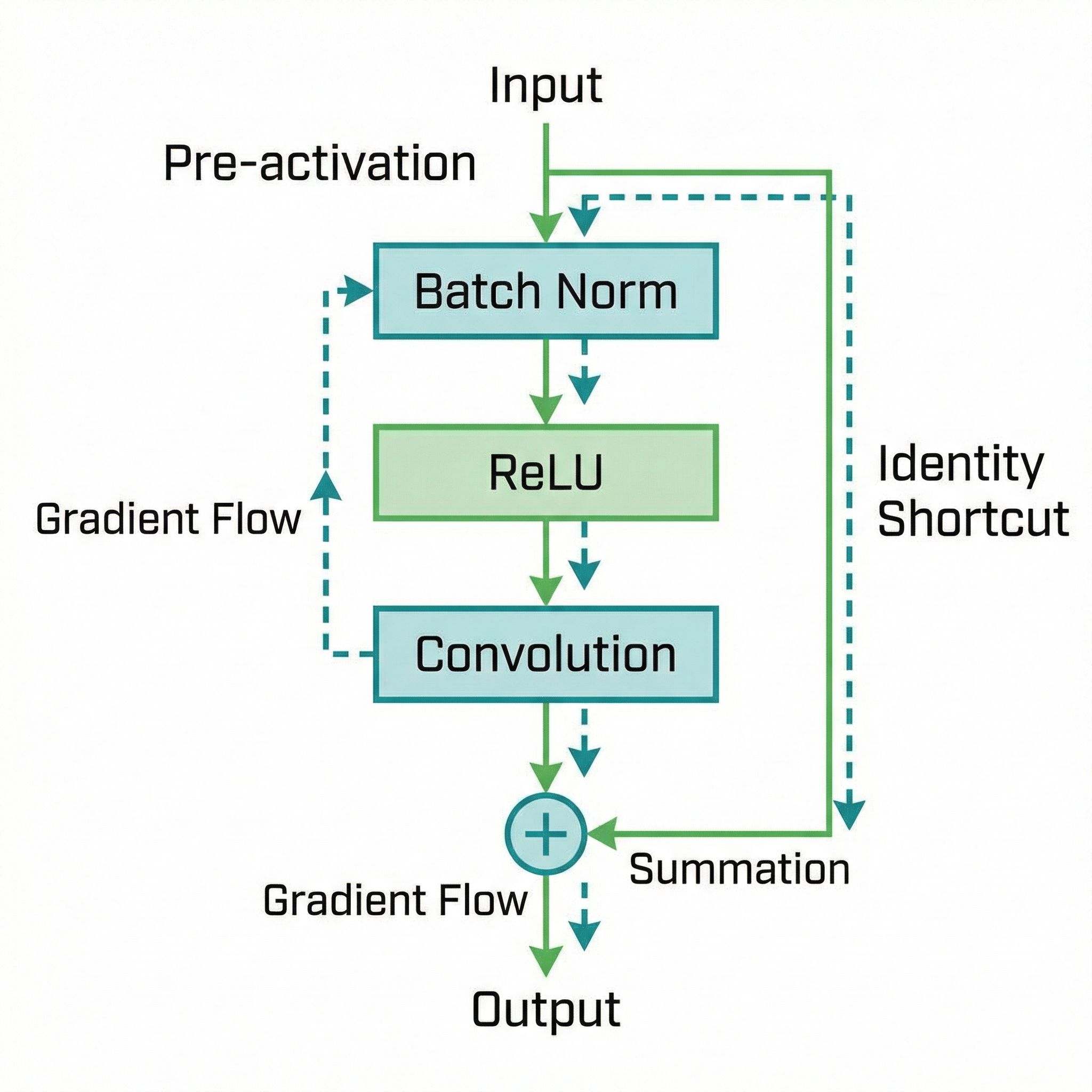
x → Conv → BN → ReLU → Conv → BN → (+x) → ReLU → output
The final ReLU applies after adding the skip connection. This seems harmless but has consequences for gradient flow.
The Problem with Post-Activation
ReLU zeros out negative values. When gradients flow backward through the post-addition ReLU, some get suppressed. The skip connection no longer provides a clean gradient highway.
For moderate depths (50-150 layers), this works. For extreme depths (1000+ layers), the accumulated suppression degrades training.
Pre-Activation Design
Move batch normalization and ReLU before the convolutions:
x → BN → ReLU → Conv → BN → ReLU → Conv → (+x) → output
Now the skip connection adds directly to the output with no intervening activation. Gradients flow through the identity branch without modification.
Mathematical Effect
With pre-activation, the gradient includes an unmodified identity term:
∂L/∂x = ∂L/∂y × (∂F/∂x + I)
The identity matrix I passes gradients unchanged. No ReLU derivative zeros them out. Signal propagation improves at every layer.
1000-Layer Networks
The paper trained a 1001-layer ResNet on CIFAR-10. With post-activation, optimization stalled. With pre-activation, the network trained successfully.
Accuracy matched shallower networks, demonstrating that extreme depth doesn't hurt when gradients flow properly. The architecture removed depth as a practical constraint.
Regularization Effect
Pre-activation also provides implicit regularization. The BN-ReLU-Conv sequence means each convolution receives normalized, rectified inputs. This stabilizes training and can reduce the need for other regularization.
Adoption
Pre-activation ResNets became standard for applications requiring very deep networks. The pattern influenced transformer design: layer normalization before attention (Pre-LN) trains more stably than post-attention normalization.
Small architectural details compound across many layers. Getting the ordering right matters.
Further Reading
More in This Series
Part of a series on Ilya Sutskever's recommended 30 papers.