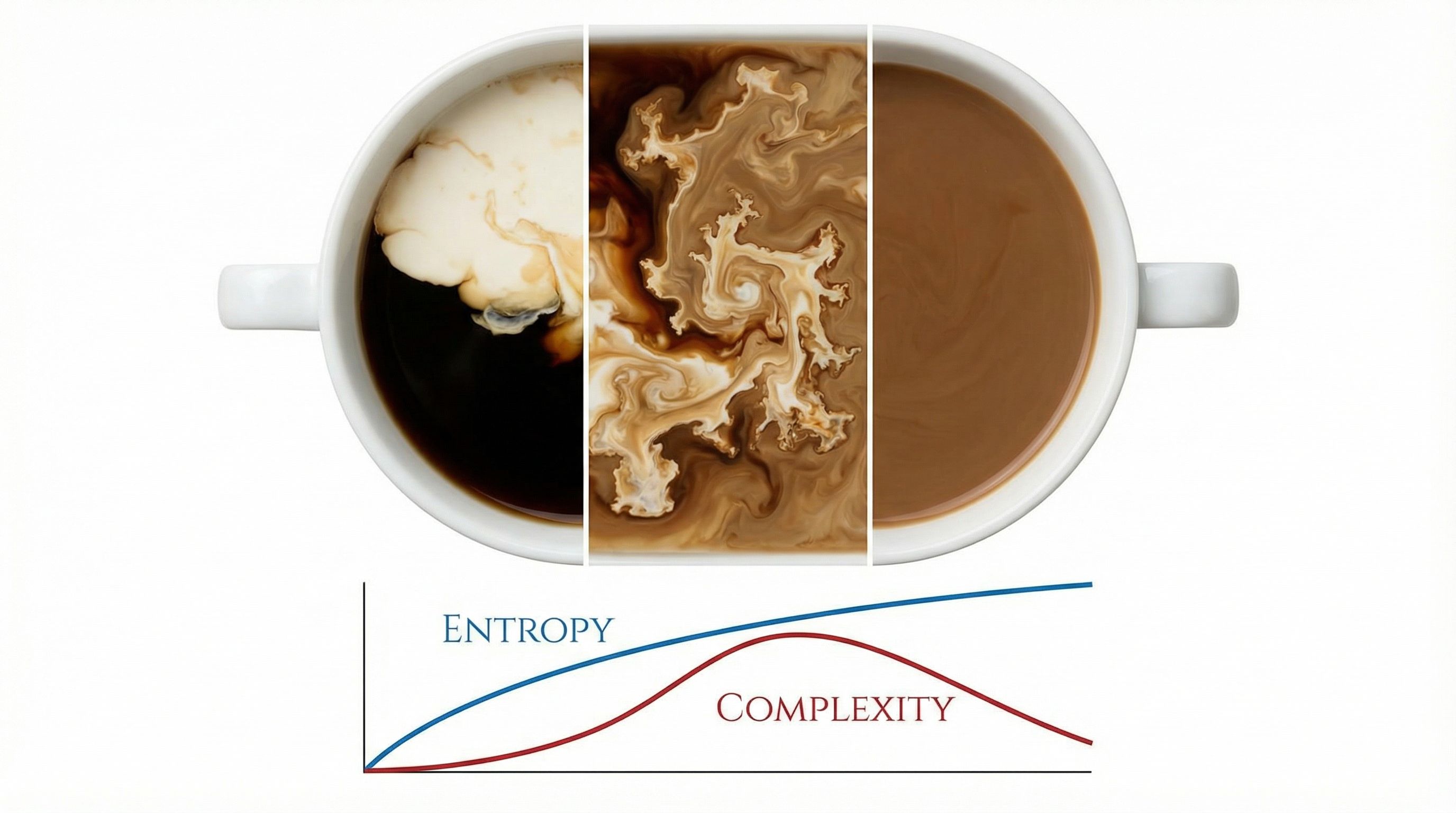
Pour cream into coffee. Watch the swirls form, then dissolve into uniform beige. You'll never see that beige spontaneously separate back into cream and coffee. The reason connects thermodynamics to how neural networks learn.
The Paper That Started It All
In 2011, Scott Aaronson wrote "The First Law of Complexodynamics," a playful title for a serious question. Ilya Sutskever included it as the first paper in his famous list of 30 papers every AI researcher should read.
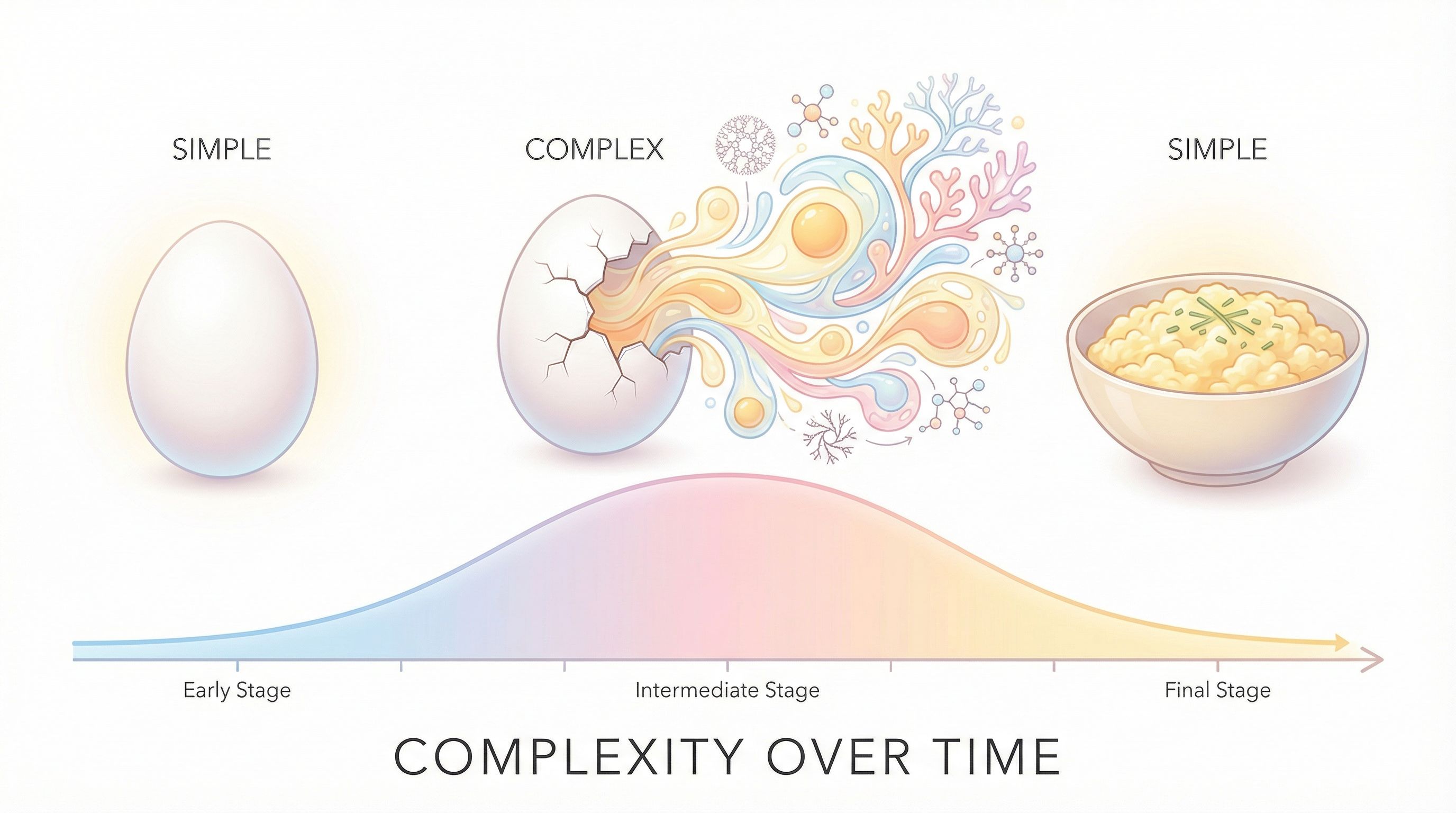
The central puzzle: entropy increases monotonically, but complexity doesn't. A raw egg has low entropy and low complexity. A cooking egg has medium entropy and high complexity as proteins denature and structures form. A fully cooked egg has high entropy but low complexity again, just uniformly cooked matter.
Aaronson's First Law
"As a system approaches thermal equilibrium, complexity first increases, then decreases."
Unlike thermodynamics' second law (entropy always increases), complexity follows an inverted-U curve. The universe gets interesting before it gets boring.
The Time Paradox
Watch a video of a ball flying through the air, then play it in reverse. The physics works both ways. Gravity, motion, energy: the equations don't care about direction. But watch an ice cube melt, then reverse it. You immediately know which version is real. Puddles don't snap together into ice cubes.
This is the paradox. The fundamental laws of physics treat past and future identically. They have no preferred direction. Yet everything in our experience moves one way: eggs break but don't unbreak, coffee mixes but doesn't unmix, we age but don't grow younger.
The difference between past and future is entropy. In the past, entropy was lower. In the future, it will be higher. This flow from order to disorder creates the arrow of time. Without it, you could remember your future as clearly as your past.
Entropy: The Enemy of Differences
Look at an apple. The skin differs from the seeds. The stem differs from the flesh. This is low entropy. Structure allows for difference. Now imagine grinding the apple into uniform paste. High entropy. Everything the same.
Entropy wants to grind everything into uniform gray soup. Hot and cold gas separated by a wall? Remove the wall and they mix until the temperature is identical everywhere. A filled balloon in a box? Pop it and the air spreads evenly. Nature pushes from unlikely (organized, specific) to likely (mixed, uniform).
The scary part about high entropy: it looks the same everywhere. Zoom in on static. Chaos at the top is identical to chaos at the bottom. Zoom in on a white wall. Perfect order also looks the same everywhere. Maximum disorder and perfect uniformity are strangely similar. Both are empty of information.
Coarse-Graining: The Key Insight
To understand why, you need to understand coarse-graining. Imagine you have a gas with 10²³ molecules. You can't track each one. Instead, you measure bulk properties: temperature, pressure, density. Many different microscopic arrangements (microstates) give the same macroscopic reading (macrostate).
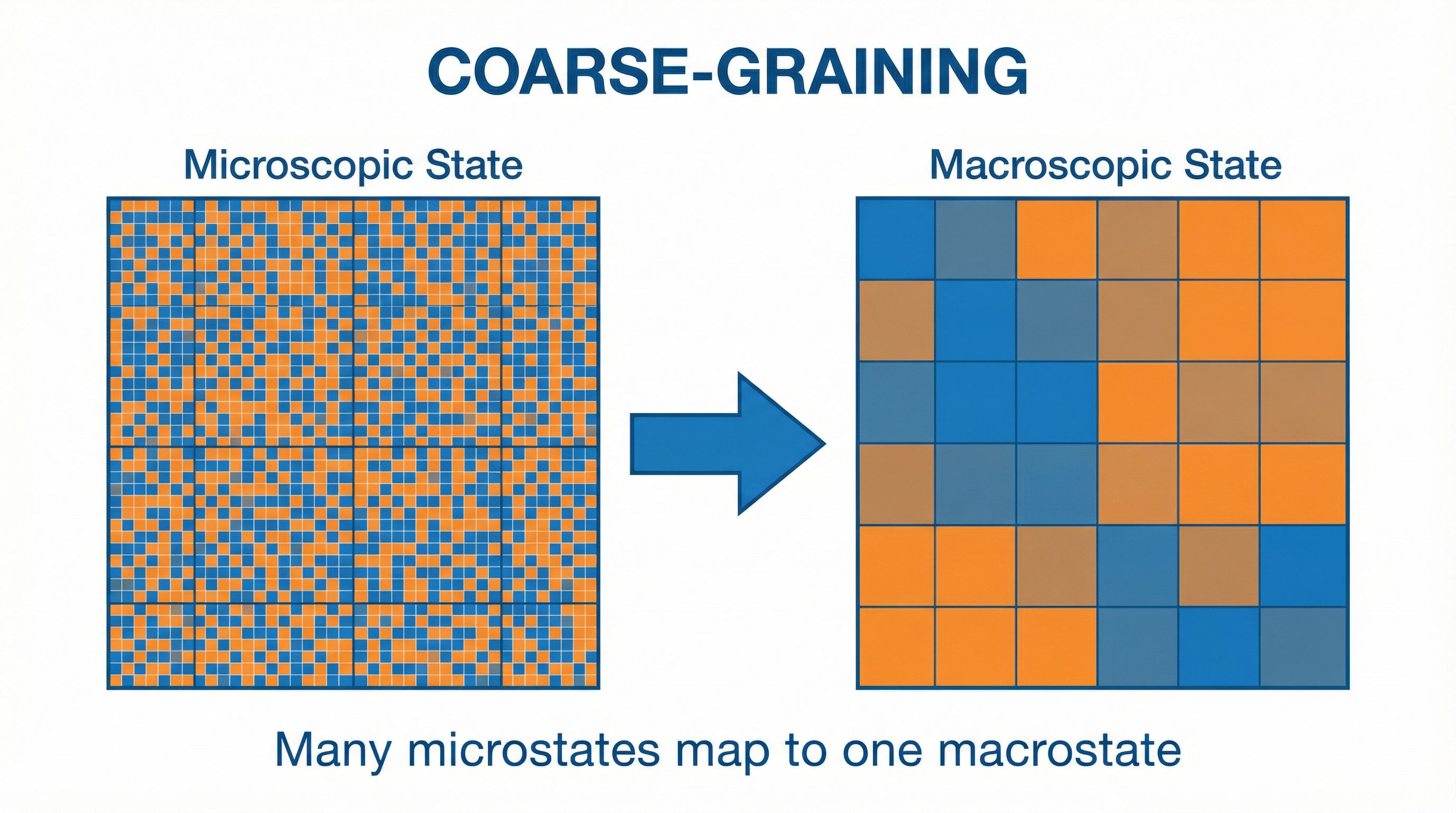
Entropy counts microstates. High entropy = many microstates compatible with what you observe. But complexity is different. Complexity asks: how hard is it to describe the macrostate? A uniform gas is easy to describe ("same everywhere"). A gas with intricate swirling patterns is hard to describe.
Start with all molecules on one side (low entropy, simple description). Let them spread. During spreading, you get complex patterns: waves, vortices, gradients. These are hard to describe. Eventually, everything equilibrates (high entropy, simple description again: "uniform").
Maxwell's Demon and the Cost of Information
In 1867, James Clerk Maxwell proposed a thought experiment: a tiny demon controls a door between two chambers of gas. It only lets fast molecules through one way, slow molecules the other. One side heats up, the other cools down. Entropy decreases. Second law violated?

It took over a century to resolve. Information is physical. The demon must observe each molecule, storing that information somewhere. When its memory fills up, it must erase old data to continue. Erasing information costs energy (Landauer's principle):
E = kBT ln(2) per bit erased
About 2.8 × 10⁻²¹ joules at room temperature
The entropy decrease the demon creates is exactly offset by the entropy increase from erasing its memory. The second law survives. Computation and thermodynamics are linked.
The Information Bottleneck: Where ML Meets Physics
Sutskever put this paper first for a reason. The information bottleneck principle, foundational to modern deep learning, is the computational cousin of complexodynamics.
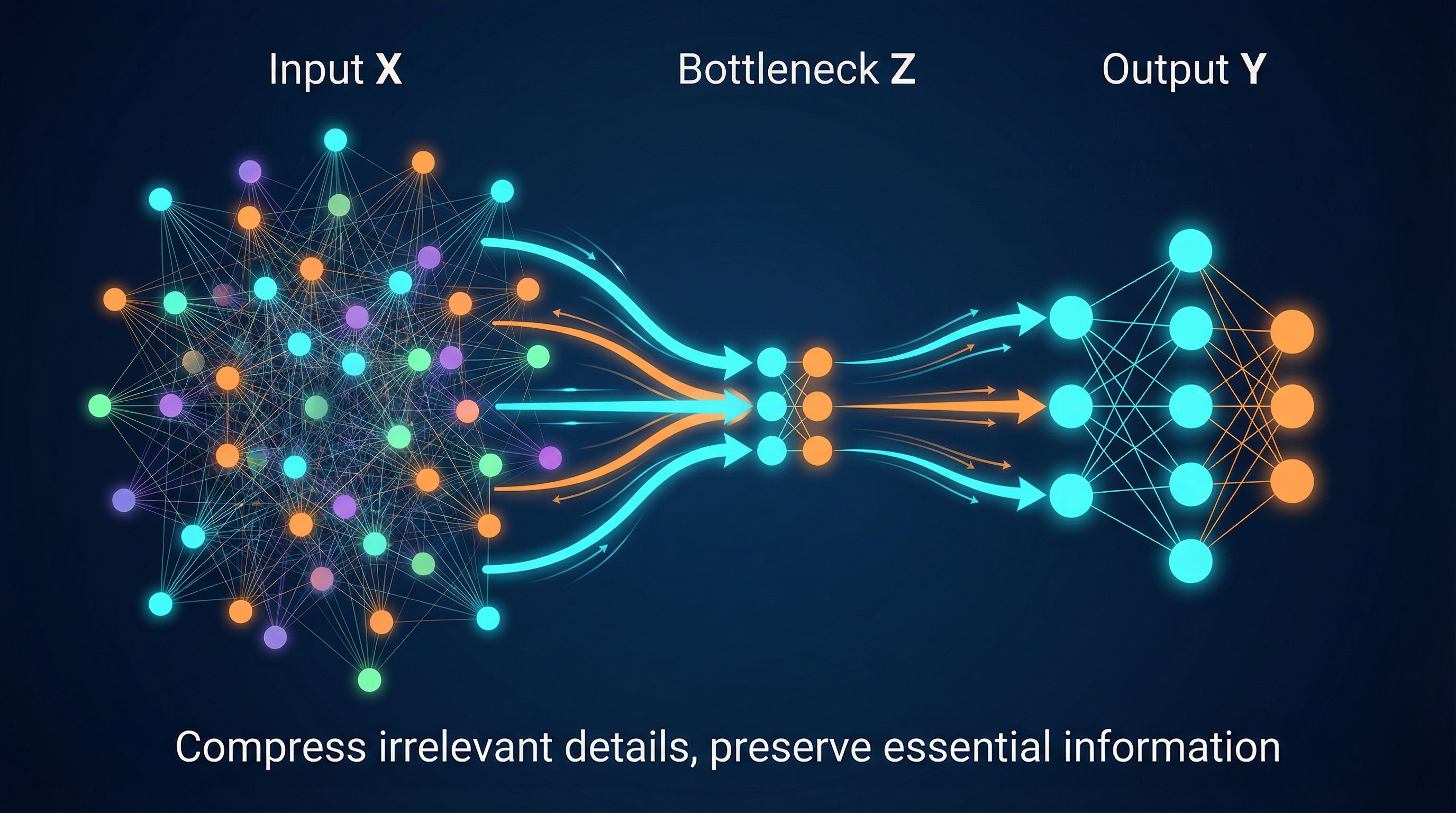
A neural network takes high-dimensional input (an image with millions of pixels) and must extract relevant features for a task (is this a cat?). It can't keep everything. So it must compress.
The information bottleneck framework says: find the representation that maximally compresses the input while preserving information about the output. This is coarse-graining. Many different images (microstates) that are all "cat" get mapped to similar representations (macrostate).
Training a neural network follows a similar arc. Early training: the network is simple. Middle training: it develops complex, task-specific features. Late training: it crystallizes into generalizable representations, lower complexity but useful complexity.
Why This Matters for AI
Complexity isn't free. Both in physics and in neural networks, creating and maintaining complex representations costs something. Understanding these costs helps build more efficient systems.
The right level of description matters. Too fine-grained and you're overwhelmed with noise. Too coarse and you miss signal. ML is about finding the right abstraction layer.
Irreversibility enables learning. Coffee can't unmix because mixing destroys information about the initial state. Neural networks that generalize well similarly "forget" irrelevant details about training examples. This forgetting is necessary.
The Deeper Question
Aaronson ends his paper with speculation: could we mathematically prove that complexity must peak before equilibrium? We still don't have a complete answer.
But there's a stranger question underneath. If entropy always increases, that means yesterday the universe was tidier than today. A billion years ago, tidier still. Follow this backward and the universe must have started in a state of extreme, improbable order. The Big Bang wasn't chaos. It was the opposite: a moment of intense concentrated structure that has been unwinding ever since.
Why did the universe start with such low entropy? We don't know. We just know we started with a full battery and have been draining it ever since.
Some physicists speculate about what happens at the end. After stars drift apart and die, only black holes remain. They slowly evaporate (Hawking radiation) over trillions of years. Eventually the universe becomes uniform radiation: no mass, no structure, no clocks. Infinite disorder. But infinite disorder looks strangely like infinite order, the same everywhere, empty of information. Some theories suggest this end state could trigger a new beginning.
What we do know: the universe creates complexity on its way to heat death. Stars form, life evolves, minds emerge. All temporary peaks in the complexity curve before final equilibrium. We are the coffee mid-swirl, the egg mid-cook, the neural network mid-training.
Further Reading
More in This Series
Part of a series on Ilya Sutskever's recommended 30 papers, connecting each to practical AI development.