CS231n taught a generation of practitioners how CNNs work. Convolutions exploit spatial structure. Pooling provides translation invariance. ReLU enables deep networks. Together, these building blocks revolutionized computer vision.
Why Sutskever Included This
Understanding CNNs requires understanding their components. CS231n provides the clearest exposition of convolutions, pooling, and training dynamics. The course material remains foundational even as architectures evolve.
Convolutional Layers
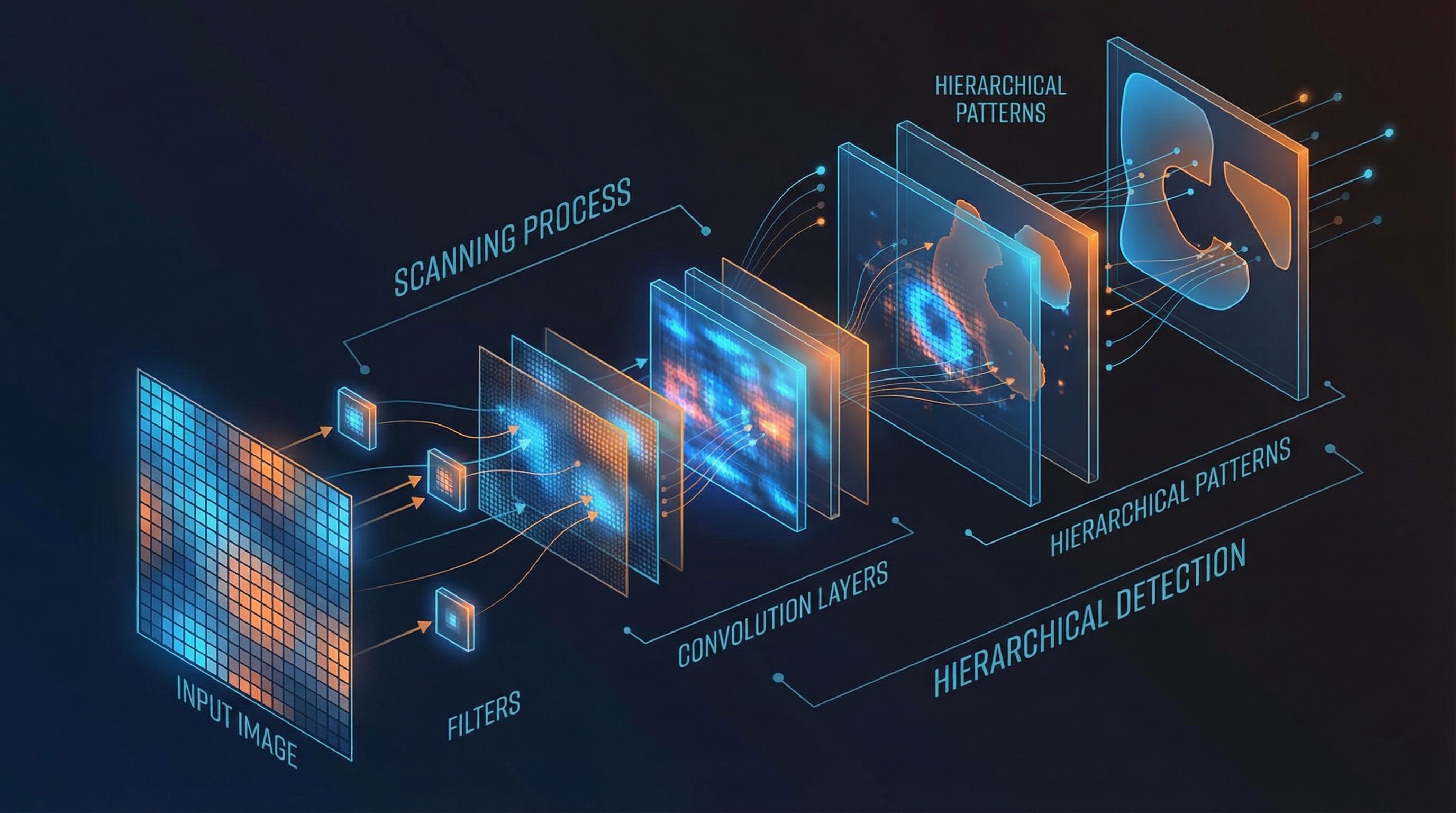
Convolutions apply learned filters to local image regions. A 3×3 filter slides across the image, computing dot products at each position. The same filter applies everywhere, with parameter sharing that exploits translation equivariance.
output[i,j] = Σ filter[m,n] × input[i+m, j+n]
Each output pixel is a weighted sum of a local input patch. The weights (filter) are learned during training.
Multiple filters produce multiple feature maps. Early layers learn edges; deeper layers learn textures, parts, and objects.
ReLU Activation
ReLU (Rectified Linear Unit) is simply max(0, x). It's fast to compute, doesn't saturate for positive inputs, and works better than sigmoid or tanh in deep networks.
The sparsity induced by zeroing negative activations may aid generalization. ReLU's simplicity belies its importance: it enabled training of much deeper networks.
Pooling
Max pooling downsamples feature maps by taking the maximum value in local regions. This provides:
Translation invariance: Small shifts in the input don't change the output.
Dimensionality reduction: Fewer spatial positions means fewer parameters in subsequent layers.
Increased receptive field: Each neuron "sees" more of the original image through stacked layers.
Architecture Progression
The course demonstrates a clear progression: k-Nearest Neighbors → Linear classifiers → Fully-connected networks → Convolutional networks. Each step adds capacity while incorporating structural assumptions.
A typical CNN stacks Conv→ReLU→Pool blocks, building hierarchical features, then flattens to fully-connected layers for classification.
Training Practices
Initialization: He initialization scales weights by √(2/n_in), appropriate for ReLU networks.
Optimization: SGD with momentum smooths updates. Learning rate scheduling (step decay, exponential) helps convergence.
Debugging: Check initial loss matches theory. Overfit a small dataset first. Monitor train/validation gaps for overfitting signals.
Further Reading
More in This Series
Part of a series on Ilya Sutskever's recommended 30 papers.