Before this paper, seq2seq models compressed entire sentences into a single vector. A 50-word sentence had to fit into 512 dimensions. Long sentences degraded. Bahdanau attention let the decoder look back at the full input, focusing on different words for each output token.
Why Sutskever Included This
This 2014 paper introduced the attention mechanism that now underlies transformers. Three years before "Attention Is All You Need," Bahdanau showed that attention could dramatically improve sequence-to-sequence learning. The paper has over 40,000 citations.
The Fixed-Length Bottleneck
Standard encoder-decoder models work in two stages. The encoder reads the input and produces a context vector. The decoder generates output from that context vector.
The problem: context is fixed-length. Whether the input is 5 words or 50, it compresses to the same size. Information loss is inevitable for longer sequences. Performance degraded as sentence length increased.
Dynamic Context
Bahdanau's insight: give the decoder access to all encoder states, not just the final one. At each decoding step, compute which encoder states are relevant and create a fresh context vector from them.
score(s_t, h_j) = v · tanh(W·s_t + U·h_j)
α_tj = softmax(score)
context_t = Σ α_tj · h_j
s_t is the decoder state, h_j are encoder states. The context vector is a weighted sum of encoder states, with weights determined by learned attention.
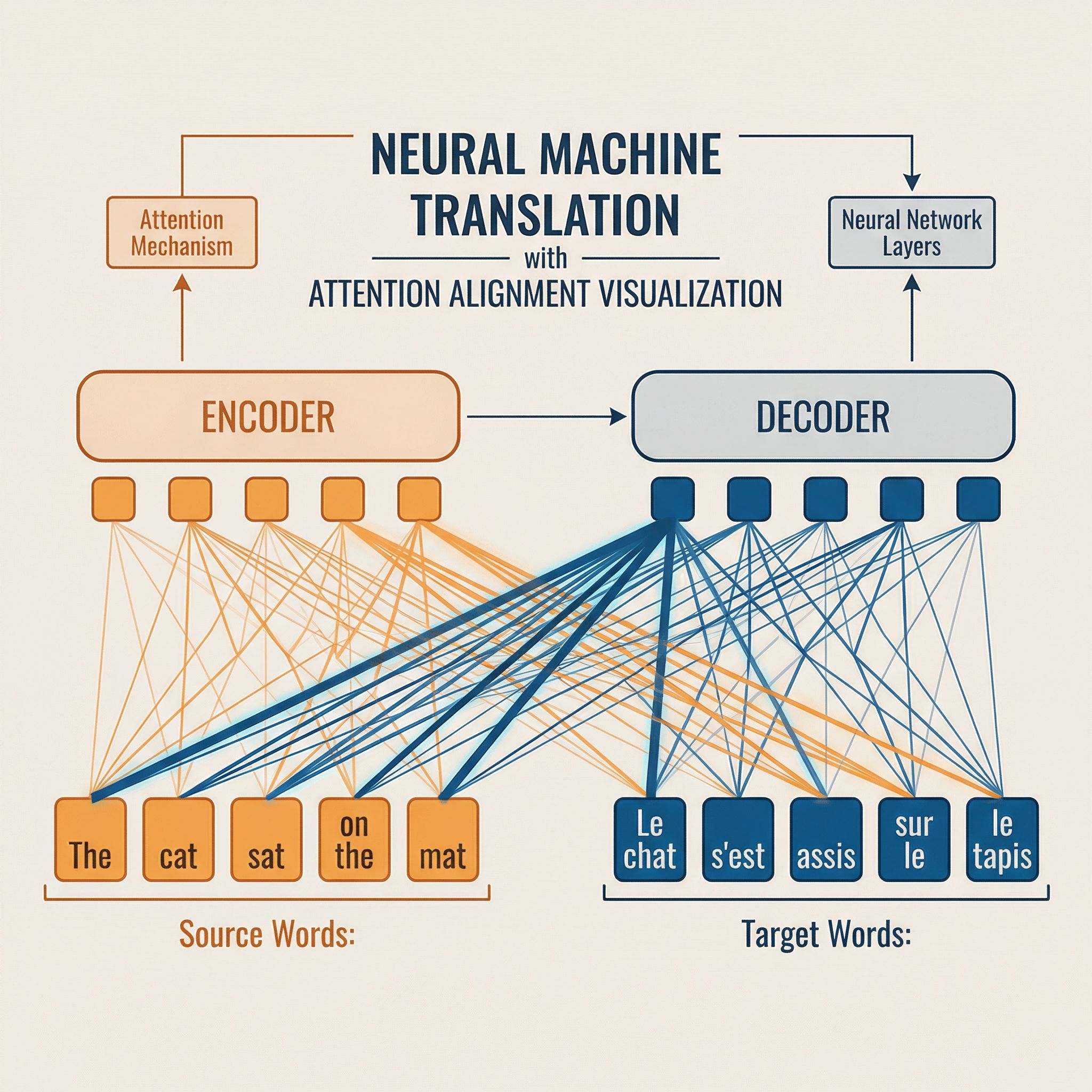
Soft Alignment
The attention weights form a soft alignment between source and target. When translating "the cat sat" to French, generating "chat" attends strongly to "cat." Generating "assis" attends to "sat."
This alignment emerges from training without supervision. The model learns which source words matter for each target word. Visualizing attention weights shows interpretable word correspondences.
Bidirectional Encoder
The paper uses bidirectional RNNs for encoding. One RNN reads left-to-right; another reads right-to-left. Concatenating their hidden states gives each position context from both directions.
For "the cat sat on the mat," the encoding of "sat" includes information from both preceding and following words. This helps attention focus on the right context.
Results
On English-French translation, attention dramatically improved performance on long sentences. Without attention, BLEU scores dropped steadily past 20 words. With attention, quality held across sentence lengths.
The improvement came from eliminating the information bottleneck. Longer sentences no longer lost information during encoding.
Additive vs. Multiplicative
Bahdanau used additive attention: score = v · tanh(W·s + U·h). Later work (Luong attention) used dot-product: score = s · h. Transformers use scaled dot-product: score = (Q · K) / √d.
Dot-product is faster (matrix multiplication vs. neural network). Scaling prevents dot products from growing too large with high dimensions.
Path to Transformers
This paper kept RNNs for both encoder and decoder, using attention only for encoder-decoder connection. Paper #13 (Attention Is All You Need) eliminates RNNs entirely, using self-attention within encoder and decoder.
The progression: attention as supplement (Bahdanau) → attention as core (Transformer) → attention at scale (GPT, Claude).
Further Reading
More in This Series
Part of a series on Ilya Sutskever's recommended 30 papers.