Add more layers, get worse results. Before ResNet, this paradox blocked progress in deep learning. A 56-layer network performed worse than a 20-layer network on both training and test sets. The problem wasn't overfitting. Optimization itself was failing.
Why Sutskever Included This
ResNet won ImageNet 2015 with 3.57% top-5 error using 152 layers. More than the competition result, the paper solved a fundamental problem: how to train networks of arbitrary depth. Skip connections became a standard component in neural architectures, from vision to language models.
The Degradation Problem
Deeper networks should be at least as good as shallower ones. Given a trained 20-layer network, a 56-layer network could copy those 20 layers and set the remaining 36 to identity (output equals input). It would match the shallower network's performance.
In practice, this didn't happen. Deeper networks degraded. Accuracy saturated, then dropped. The optimization landscape of deep plain networks made finding good solutions difficult.
Residual Learning
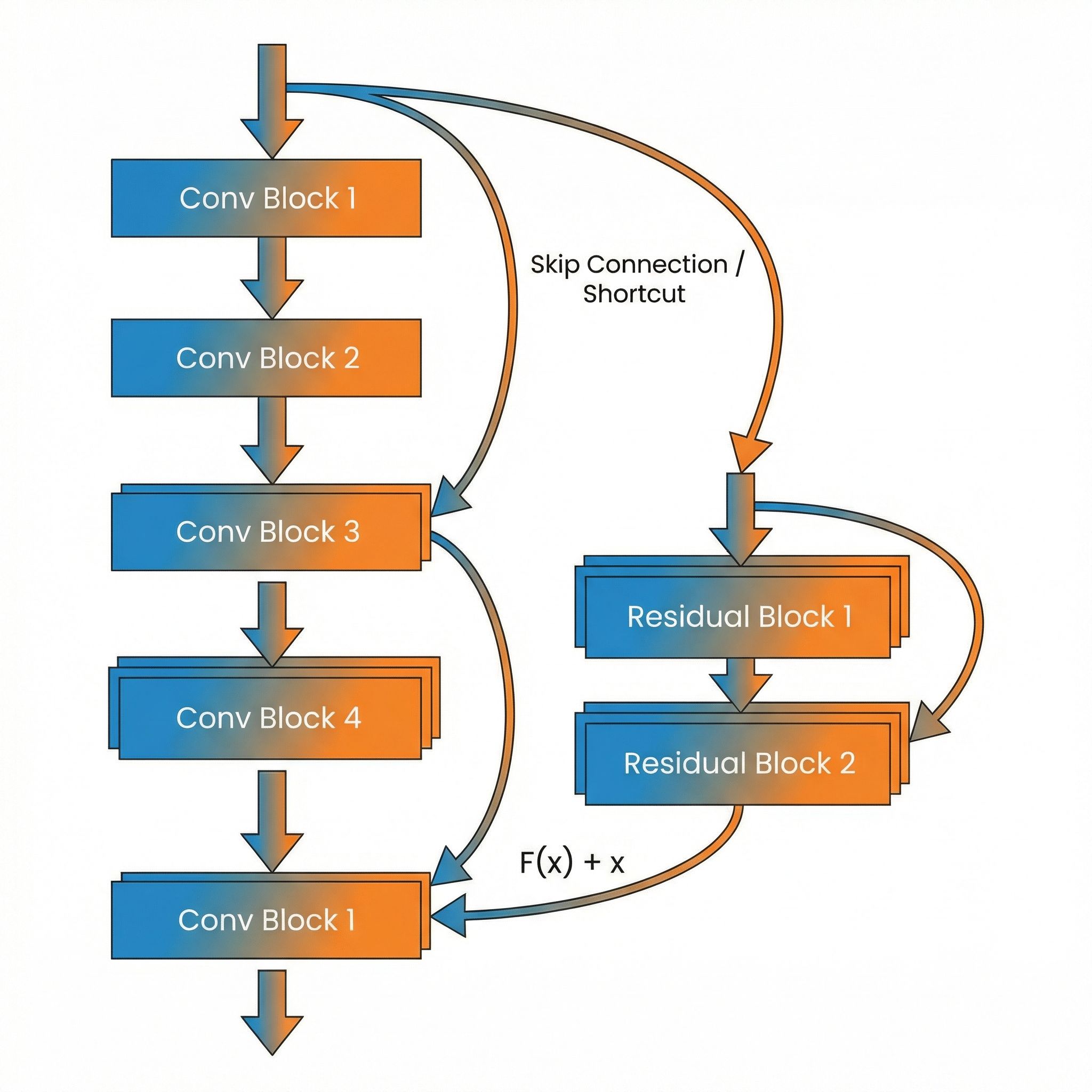
Instead of learning H(x) directly, learn F(x) = H(x) - x. Then compute H(x) = F(x) + x. The network learns the residual (the difference from identity) rather than the full transformation.
Plain block: y = F(x)
Residual block: y = F(x) + x
The "+x" is the skip connection. It's parameter-free and adds no computation.
Why This Works
Easy identity: When the optimal transformation is identity (do nothing), the residual F(x) should be zero. Driving weights toward zero is easier than learning the identity mapping. Layers that don't help can effectively disappear.
Gradient highways: Backpropagation through a residual block gives ∂L/∂x = ∂L/∂y × (∂F/∂x + I). The identity matrix I ensures gradients flow backward even if ∂F/∂x is small. Skip connections prevent vanishing gradients.
Composable refinement: Each residual block adds a refinement to its input. The network builds up transformations incrementally rather than computing each layer's output from scratch.
Architecture
ResNet stacks residual blocks. Each block contains two or three convolutional layers with batch normalization and ReLU activations. The skip connection bypasses these layers and adds input to output.
When dimensions change (more channels or spatial downsampling), the skip connection uses a 1x1 convolution to match dimensions. These projection shortcuts add parameters but maintain the residual structure.
Depth Records
ResNet-152 trained successfully. The authors also tested ResNet-1202 on CIFAR-10. It trained without optimization problems, though it slightly overfit due to the small dataset. The architecture removed depth as a limiting factor.
Plain networks of the same depth failed to train. The skip connections were essential, not optional.
Beyond Vision
Residual connections appear throughout modern deep learning. Transformers use them around attention and feed-forward layers. Diffusion models stack residual blocks. Any architecture with many sequential layers benefits from this pattern.
Paper #15 in this series (Identity Mappings in ResNet) refines the design further, showing that pre-activation (batch norm and ReLU before convolution) improves gradient flow.
Implementation Notes
Skip connections are cheap. A single addition per block, no learned parameters for identity shortcuts. The computational overhead is negligible; the training benefit is substantial.
Initialization matters. ResNet blocks typically use small initial weights so early training stays near identity mappings. The network gradually learns to deviate from identity as training progresses.
Legacy
Before ResNet, practitioners debated optimal network depth. After ResNet, depth became a hyperparameter to increase until overfitting or compute limits hit. The paper shifted the question from "how deep can we go" to "how deep should we go."
The insight that identity mappings help optimization influenced architecture design broadly. Highway networks, DenseNets, and countless variants build on this foundation.
Further Reading
More in This Series
- Paper #1: Why Coffee Mixes But Never Unmixes
- Paper #2: The Unreasonable Effectiveness of RNNs
- Paper #3: Understanding LSTM Networks
- Paper #4: Recurrent Neural Network Regularization
- Paper #5: Keeping Neural Networks Simple
- Paper #6: Pointer Networks
- Paper #7: AlexNet
- Paper #8: Order Matters - Seq2Seq for Sets
- Paper #9: GPipe
Part of a series on Ilya Sutskever's recommended 30 papers, connecting each to practical AI development.