
#30
Lost in the Middle
Language models struggle with information in the middle of long contexts. The U-shaped attention pattern.
Read moreIlya Sutskever's recommended reading list. The 30 research papers he considers essential for understanding AI.
Language models struggle with information in the middle of long contexts. The U-shaped attention pattern.
Read more
Combining retrieval with generation. External knowledge grounds language models in facts.
Read more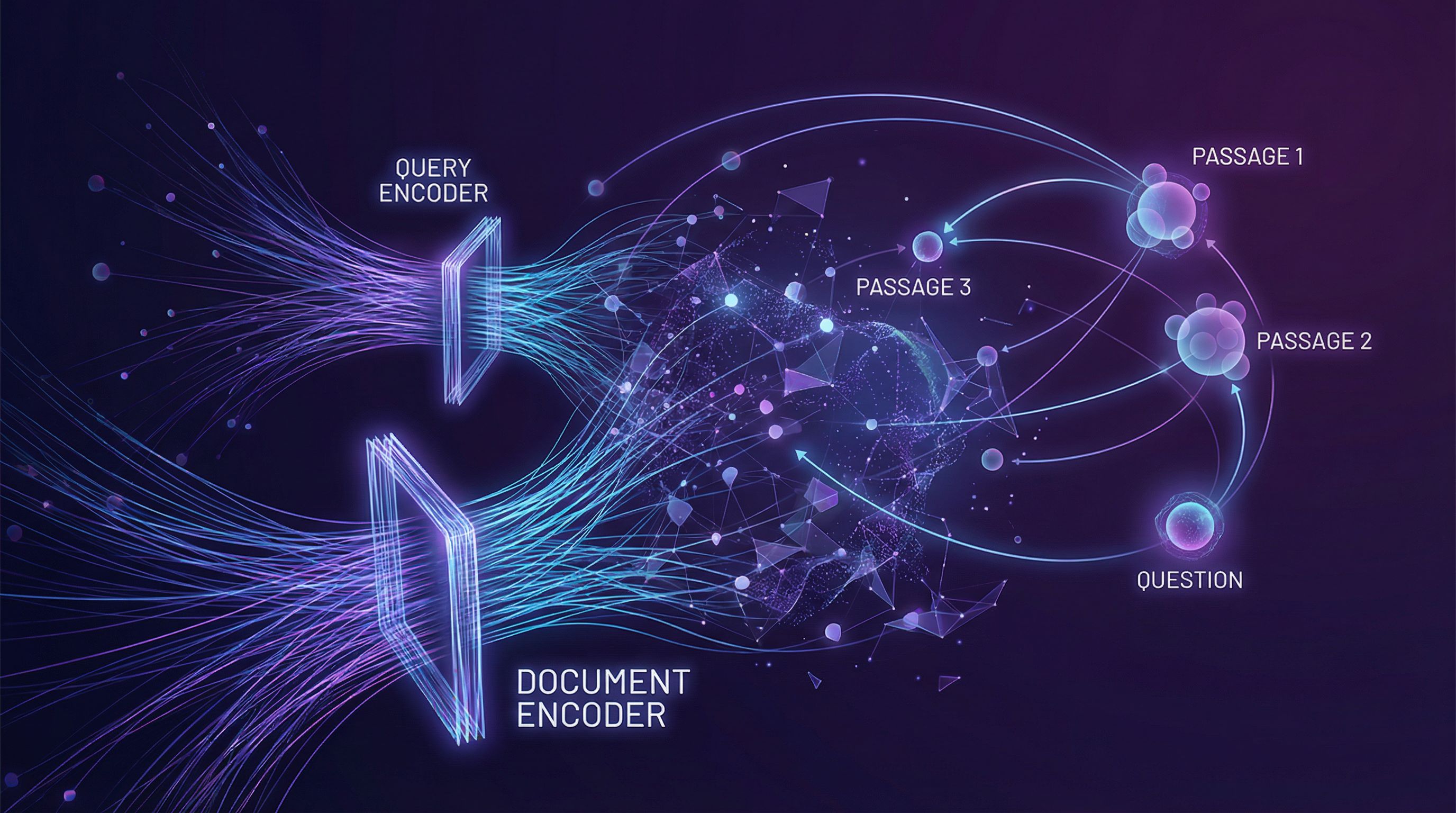
Learning embeddings for questions and passages. Dual encoders and contrastive learning beat BM25.
Read more
Predicting multiple tokens at once improves sample efficiency and enables speculative decoding.
Read more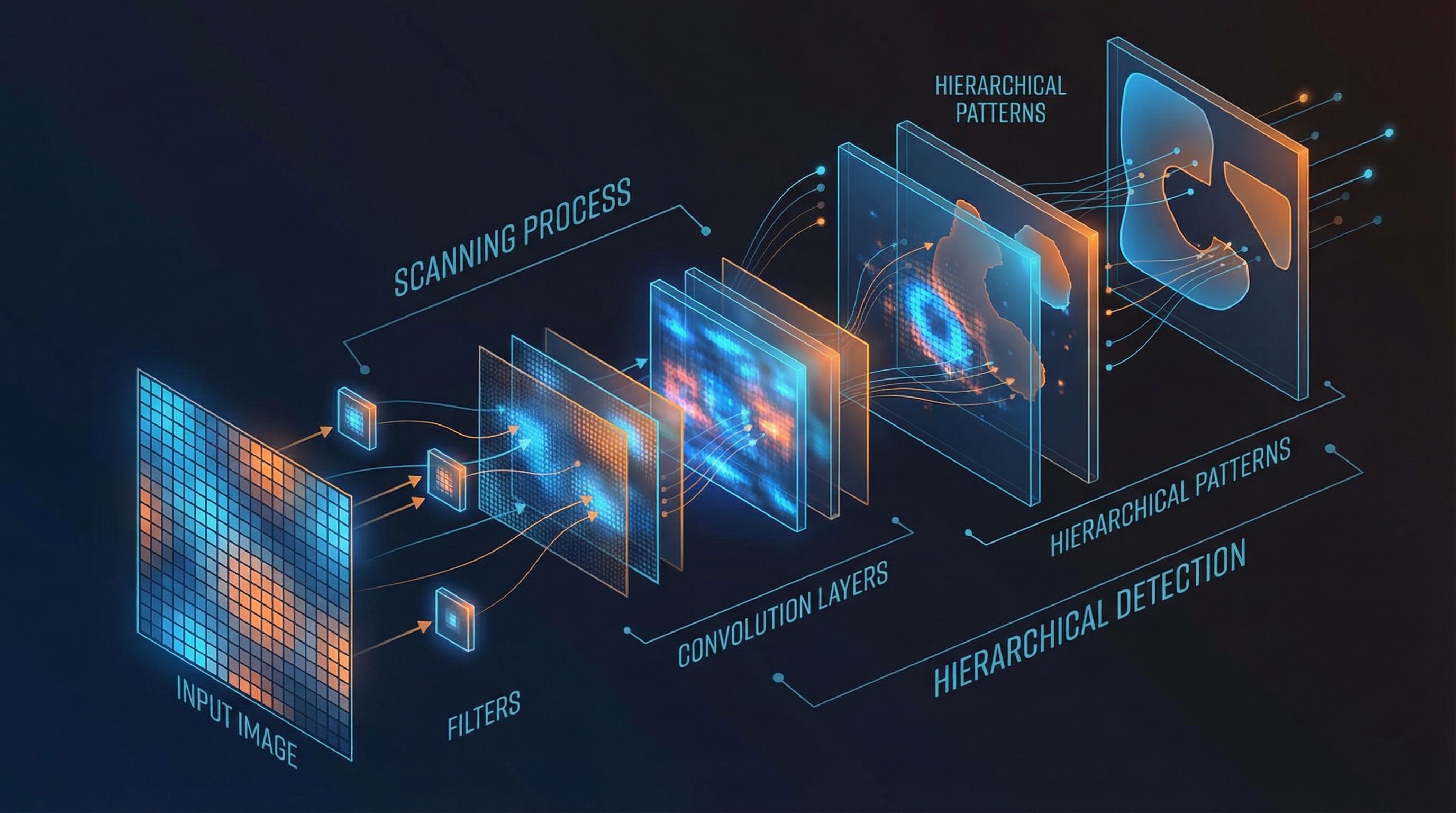
Convolutional layers, pooling, ReLU, and backpropagation. Stanford's CS231n course distilled.
Read more
The shortest program that outputs a string. Incompressibility equals randomness.
Read more
Formal definitions of machine intelligence. Recursive self-improvement and the path to superintelligence.
Read more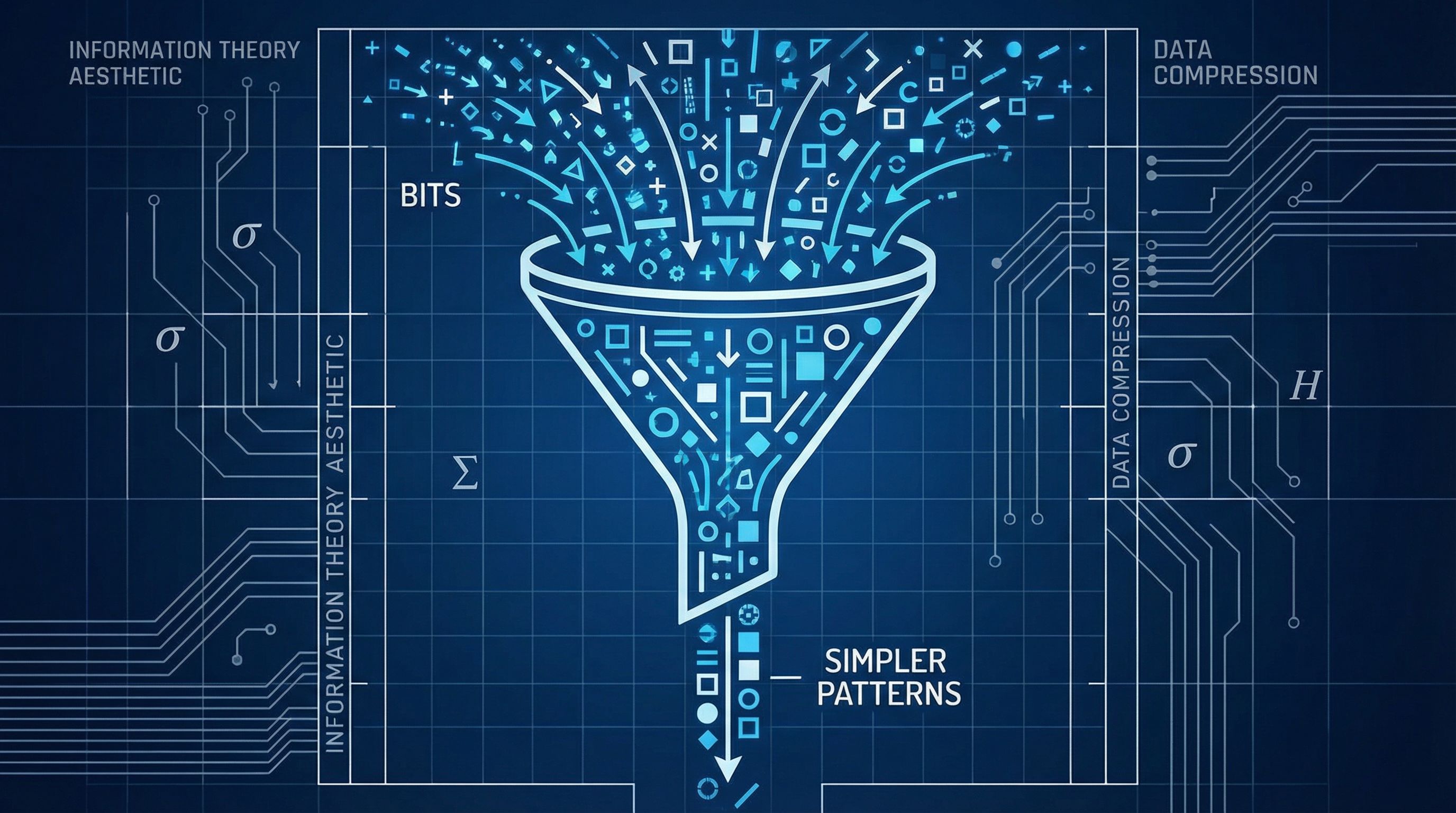
Minimum Description Length balances model complexity against fit. Occam's razor made mathematical.
Read more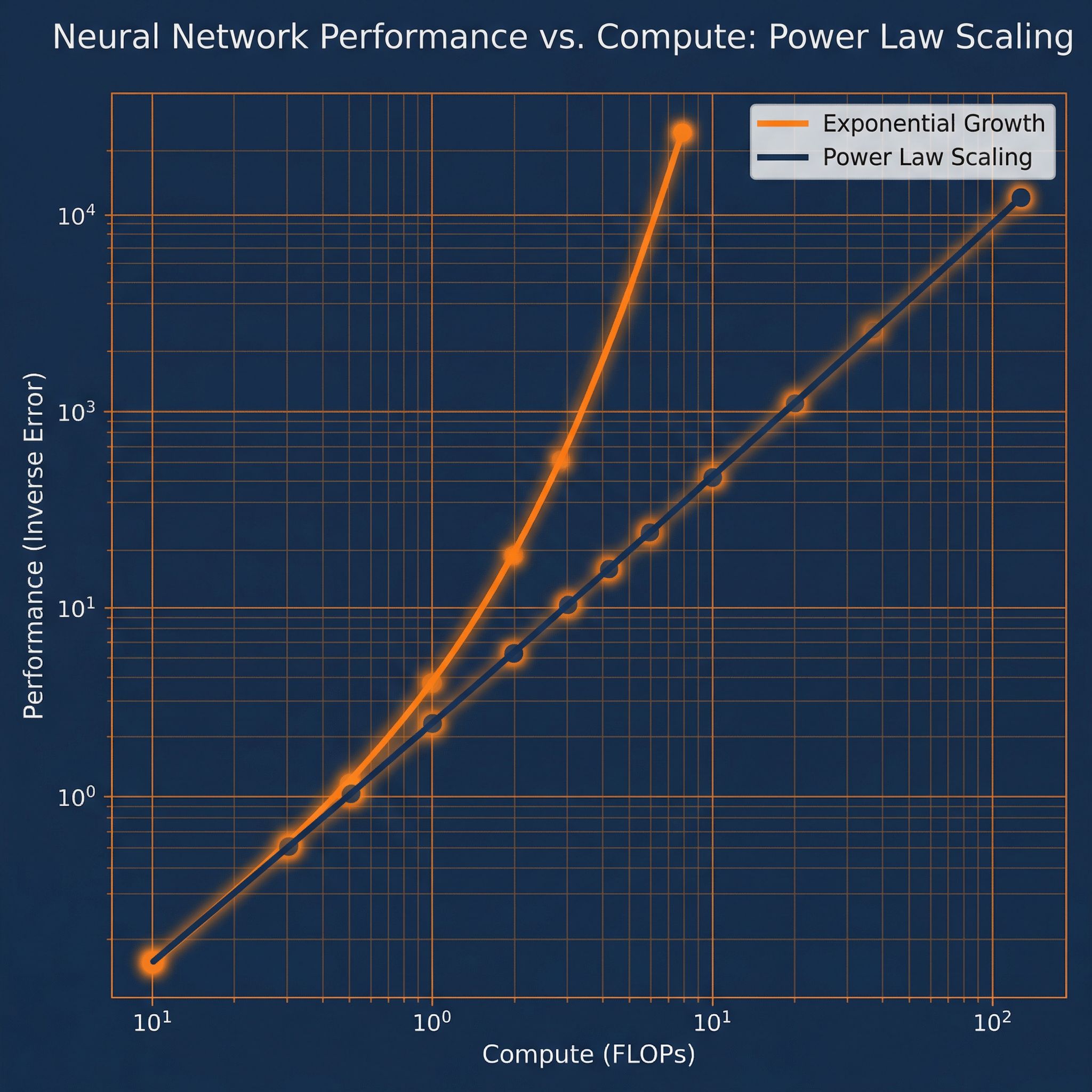
Power laws for neural language models. How performance scales with compute, data, and parameters.
Read more
Training speech models without frame-level alignment. The blank token and alignment-free learning.
Read more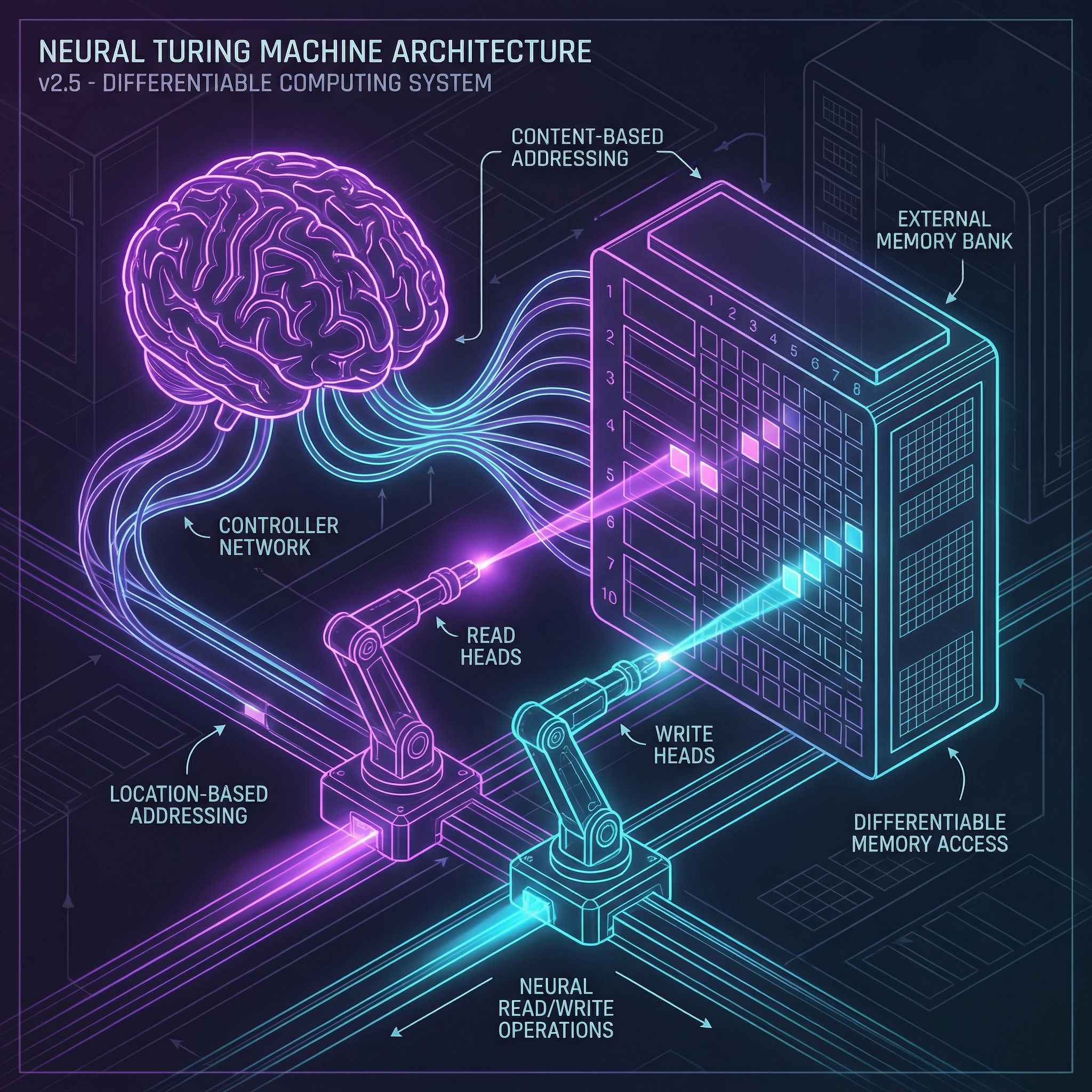
Differentiable computers with external memory banks. Content and location-based addressing.
Read more
Why does coffee mix but never unmix? Entropy, coarse-graining, and the arrow of time.
Read more
Memory slots that attend to each other enable multi-step reasoning.
Read more
Learning to generate data by encoding it into structured latent spaces. ELBO and the reparameterization trick.
Read more
Relation Networks compare all object pairs to answer questions about relationships.
Read more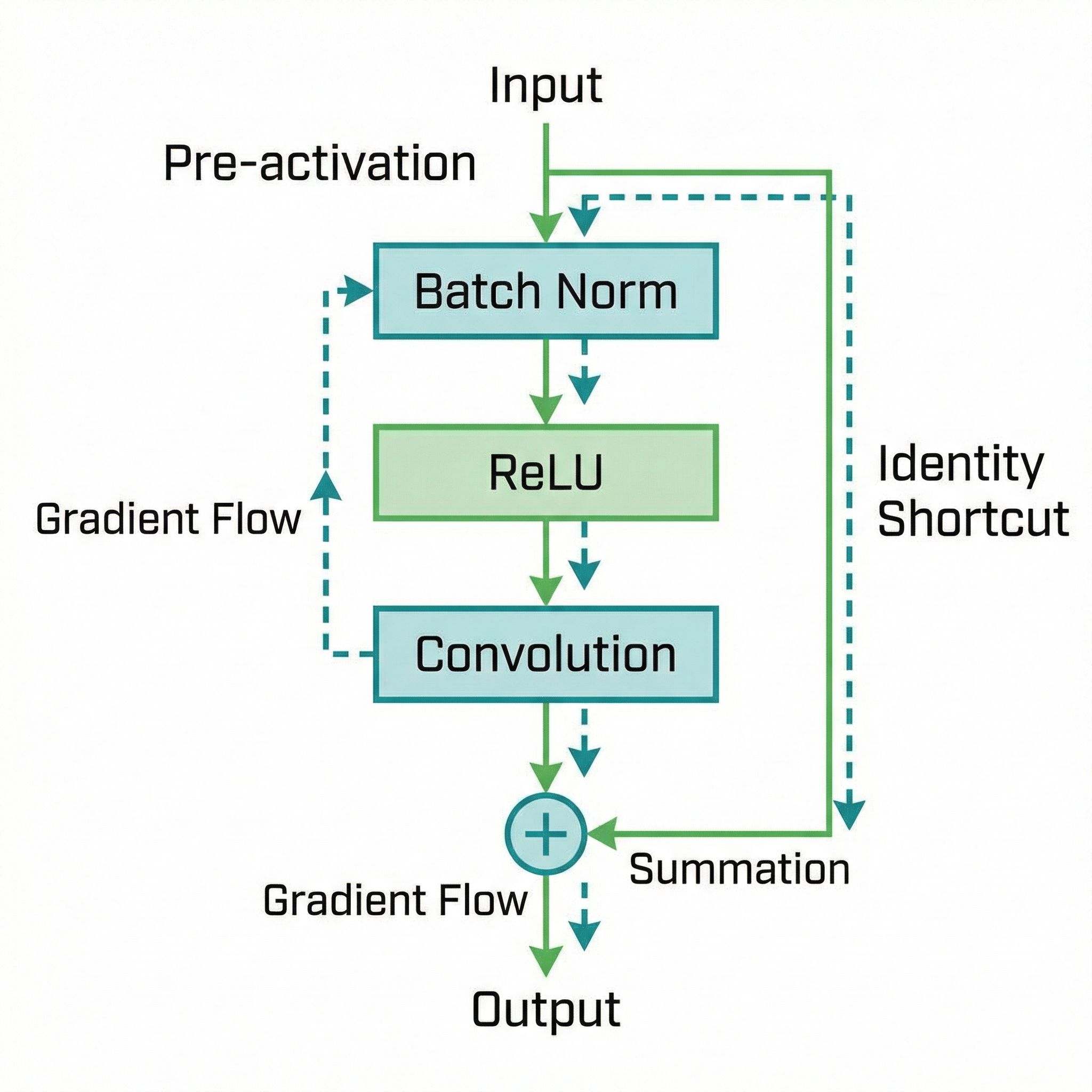
Moving activation before convolution enables training 1000-layer networks.
Read more
Neural machine translation by jointly learning to align and translate. The original attention mechanism.
Read more
The Transformer architecture replaced recurrence with self-attention. Foundation of GPT, BERT, and modern AI.
Read more
Message passing on graphs. Nodes aggregate information from neighbors to learn representations.
Read more
Exponentially expanding receptive fields without losing resolution. WaveNet's secret for audio generation.
Read more
Skip connections let gradients flow through 152 layers. Learning residuals instead of direct mappings.
Read more
Pipeline parallelism for training giant neural networks. Micro-batches keep accelerators busy.
Read more
Sets have no order, but neural networks need sequences. How to handle permutation invariance.
Read more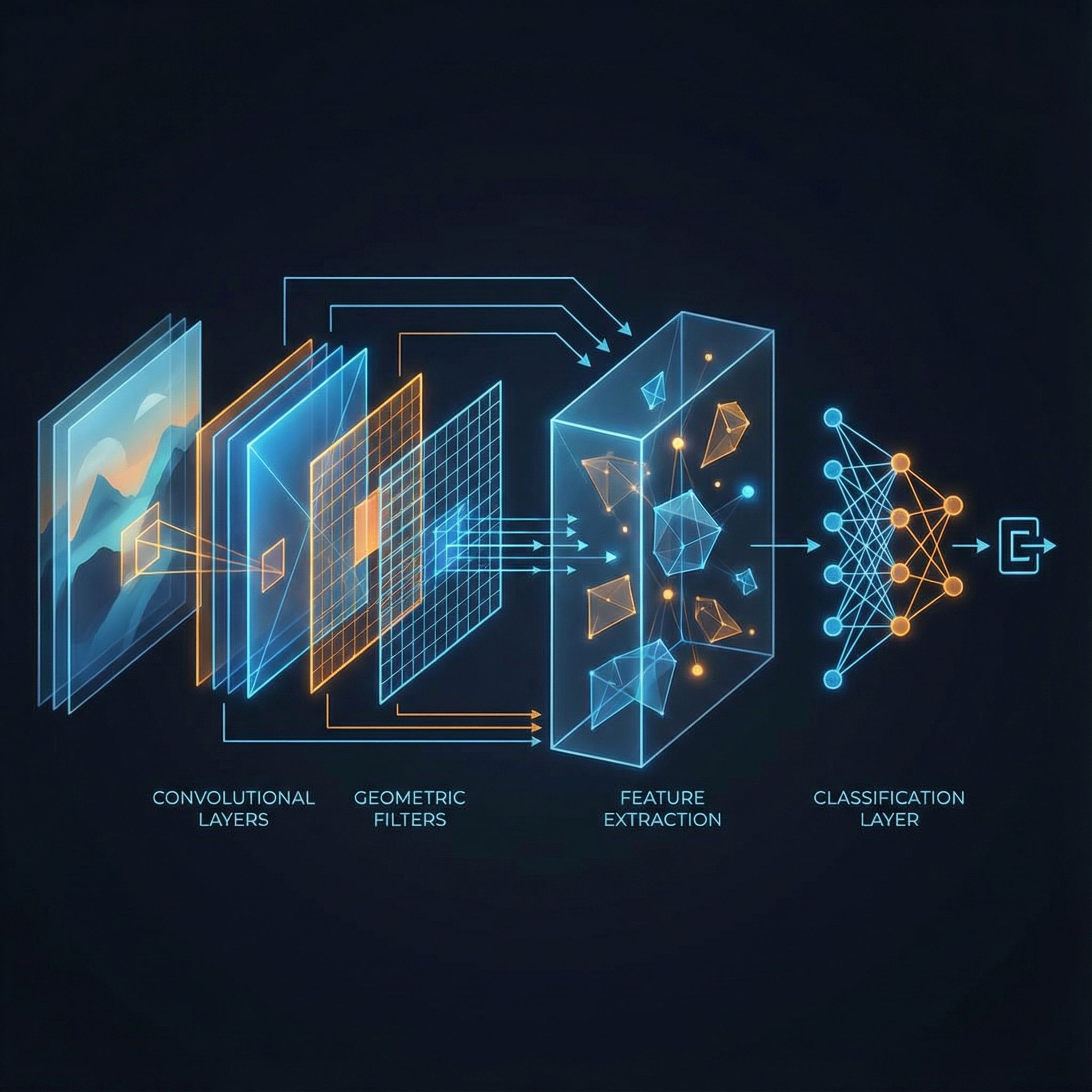
Krizhevsky, Sutskever, and Hinton's 2012 ImageNet victory proved deep learning could outperform hand-engineered computer vision.
Read more
Vinyals, Fortunato, and Jaitly repurposed attention to point at input positions instead of blending hidden states.
Read more
Hinton and van Camp showed that penalizing weight complexity leads to better generalization.
Read more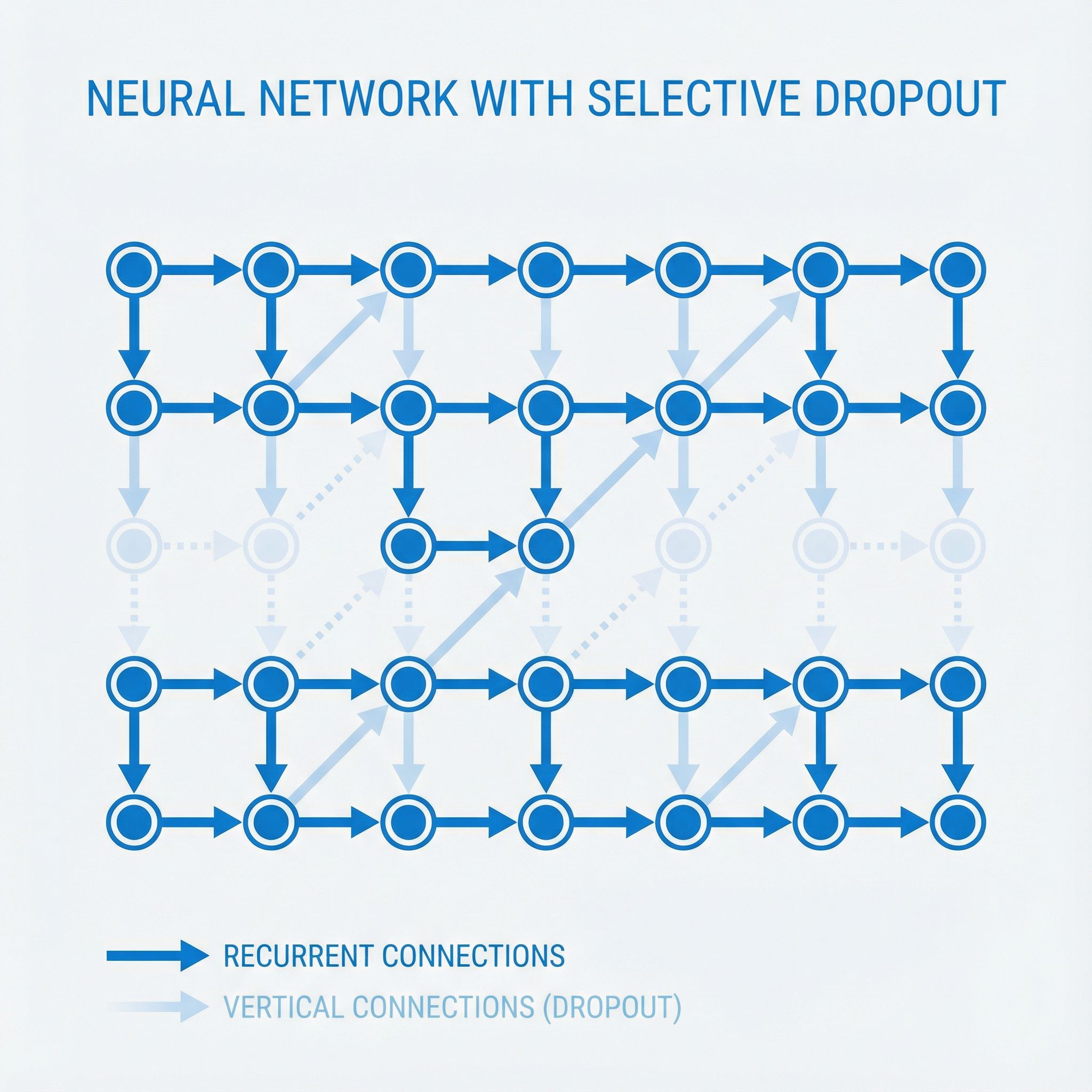
Zaremba, Sutskever, and Vinyals figured out how to apply dropout to LSTMs without breaking them.
Read more
Christopher Olah's 2015 post explained LSTM gates with clarity that textbooks lacked.
Read more
Karpathy's famous 2015 post showed RNNs could generate Shakespeare and Linux code by predicting one character at a time.
Read more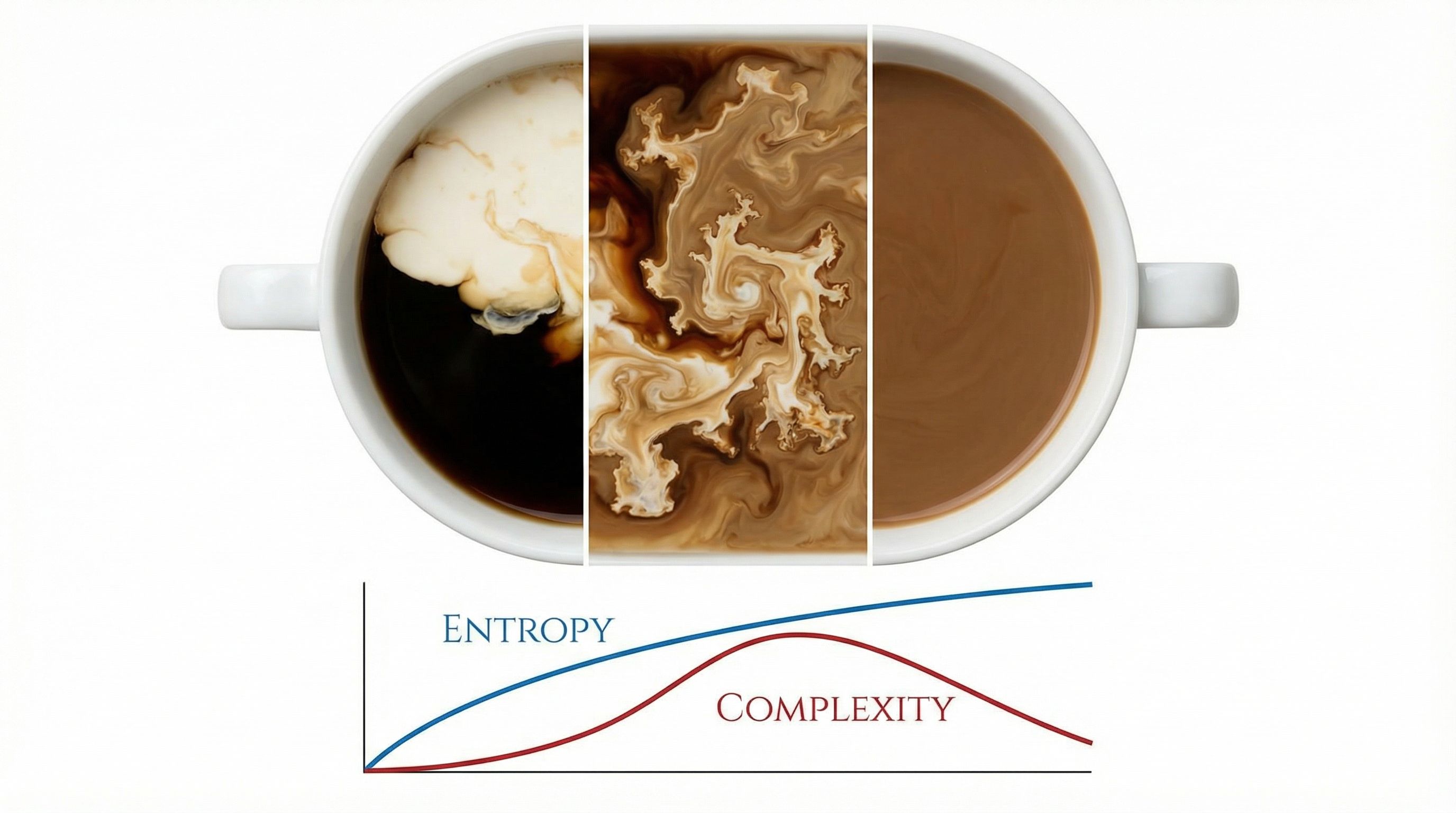
Scott Aaronson's First Law of Complexodynamics explains why complexity rises, peaks, then falls.
Read more